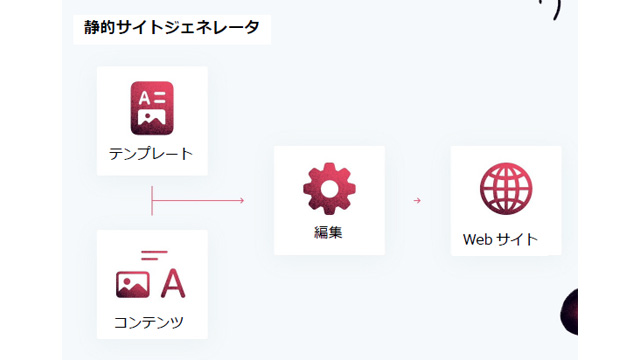
This section provides an overview of what is necessary for success in SEO, whether you are running a Jamstack website or not.
 Author: Nebojsa Radakovic March 9, 2021
Author: Nebojsa Radakovic March 9, 2021

4. Is there anything else that can be done to impact the performance of the website?
There are also several other points to be aware of. Please ensure that they are being done correctly to improve the performance of the website.
4-1 Performance Budget
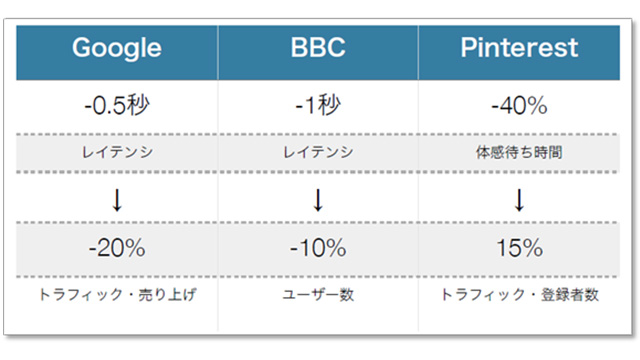
If you are launching a new website or planning a renewal, please pay attention to the performance budget. To improve the balance of performance issues without compromising functionality or user experience, make sure to establish the underlying objectives and overall approach in the early stages of web development.
It was also very helpful during the reconstruction of our website. If you decide to take this approach, please start planning using the performance budget calculator.
4-2 URL Structure, Site Structure, Navigation
Whether the URL, website structure, internal links, and navigation are clear affects the impression of the website from the perspective of users and crawlers. The importance, impact, and complexity of the website structure increase significantly depending on the size of the website. There are several general rules to follow.
Google believes that the fewer clicks it takes to reach a page from the homepage, the better it is for the website.
By planning the structure of the website in parallel with keyword research, you can enhance the authority of the website and efficiently and evenly distribute it across the pages, increasing the likelihood of appearing in search results for all targeted keywords.
It is essential for the website menu to have clear categories, keywords, and links to the main pages. Pay attention to internal links. This means that articles related to a topic should only link to paragraphs related to that topic. Avoid having so-called orphan pages that are not linked from any page of the website.
Finally, use a short URL that emphasizes keywords, separating words with hyphens for readability. Make sure the URL clearly represents the content of the page as much as possible.
4-3 JavaScript
Reduces the amount of JavaScript used on the website. It's very simple. While JS enhances the functionality of the website, it can also degrade the website's performance depending on its usage.
In the new world of Core Web Vitals, the actual execution time of JS has the greatest impact on First Input Delay (FID).
In general, third-party scripts are delayed or removed. This improves JS performance, and non-essential scripts are postponed as much as possible. Always place JS code below the main content. This way, it will not degrade the user experience. By using Google Tag Manager, for example, you can simplify it with custom JS.
4-4 Images
The best way to save on the overall page size and loading speed is through image optimization. First, you can take advantage of lazy loading.
The second is to use WebP or AVIF image formats, which are optimized to be smaller in file size than JPG (or PNG).
As a result, the website will become faster. By optimizing and compressing images and delivering them from a CDN, you can improve the LCP (Largest Contentful Paint) score. Keep in mind that image optimization also includes elements of web design and UX. It's not just a matter of simply resizing images.
Most static site generators attempt to provide native image processing solutions. If you are using Gatsby, you will use the gatsby-image package, which is designed to work seamlessly with Gatsby's native image processing capabilities utilizing GraphQL and Sharp. It not only helps with image optimization but also automatically applies blur-up effects and lazy loading for images that are not currently displayed on the screen. You can also use the new gatsby-plugin-image (currently in beta), which improves LCP and adds support for AVIF.
Starting from version 10.0.0, Next.js includes the Image Component and Automatic Image Optimization. Images are lazy-loaded by default, rendered in a way that avoids Cumulative Layout Shift issues, provided in modern formats like WebP if supported by the browser, and optimized on demand based on user requests.
Hugo users can apply this shortcode for image resizing, lazy loading, and progressive loading. Alternatively, you can use an open-source solution like ImageOptim to run it in the images folder. Finally, Jekyll users can do things like what is mentioned here or set up Imgbot.
Let's keep in mind that performance metrics are not everything. For example, if the search results for your niche/topic/keyword are filled with pages that use videos or flashy animations, it is undoubtedly a concern for most people regarding performance scores (though this is a somewhat vague discussion). However, that does not mean that pages with high-performance scores will necessarily rank higher. Moreover, there is a possibility that they may not convert well with the target audience. Why? Rankings are a multi-faceted game, and performance is just one part of this puzzle.
5. Indexing and Crawlability

No matter how wonderful the content you create is, it is meaningless if it is not properly indexed and crawled by search engines. Allowing search engines to crawl your website is one thing. Ensuring that bots can crawl and discover all the necessary pages, while excluding pages you do not want them to see, is another issue.
5-1 Robots.txt and XML Sitemap
The robots.txt file provides information about which files or folders you want search bots to crawl and which files or folders you do not want them to crawl. It helps keep entire sections of a website private (for example, every WordPress website has a robots.txt file that prevents bots from crawling the admin directory). It can also prevent images and PDFs from being indexed, or prevent internal search results pages from being crawled and displayed in search engine results.
Please ensure that the robots.txt file is located in the top-level directory of the website, indicates the location of the sitemap, and does not block the content/sections of the website that you want to be crawled.
On the other hand, a sitemap is an XML file that provides valuable information to crawlers about the structure of a website and its pages. It informs crawlers which pages are important for the website, how important they are, when the pages were last updated, how frequently they are changed, and whether there are alternative language versions of the pages.
A sitemap helps search engine crawlers index pages more quickly, especially when there are thousands of pages or when the website structure is deep. Once you create a sitemap, let the big G know using Google Search Console.
Gatsby users can utilize a plugin that automatically creates robots.txt and sitemap.xml. Jekyll users can either use the sitemap plugin or quickly generate a sitemap manually by following this tutorial. For robots.txt, you just need to add a file to the root of the project.
Hugo comes with a built-in sitemap template file. On the other hand, for robots.txt, you can generate a customized file just like other templates. If you are using Next.js, the easiest and most common way is to use a solution like this to generate the sitemap and robots.txt during the build process.
5-2 Duplicate Content, Redirects, Canonicalization

We all want Google to recognize that our content is original. However, this can sometimes become an issue. This can happen when a single page is accessed via multiple URLs (both HTTP and HTTPS), when original articles are shared on platforms like Medium, or when different pages have similar content.
What kind of problems are there, and what should be done in such cases?
The act of having the same or slightly different content on several pages or websites is considered duplicate content. There is no one-size-fits-all answer to the question of how to mark similar content as duplicate. The answer varies and depends on the interpretation of Google and other search engines. For example, e-commerce sites may display the same content on multiple item pages, but it is rarely flagged as duplicate content.
However, intentionally using the same content across multiple pages or domains can significantly damage the original page or website.
Why? This makes it difficult for search engines to determine which pages are more relevant to search queries. If you do not explicitly communicate to Google which URL is the original/canonical, Google may make a selection, potentially boosting unexpected pages.
There are several ways to address duplicate content, depending on the situation.
If duplicate content appears on one or several internal pages, the best approach is, of course, to rewrite the content. However, in cases where the same topic/keyword/product is covered, consider setting up a 301 redirect from the duplicate pages to the original page. URL redirects are also a good practice to inform search engines of changes made to the structure of the website.
For example, if you want to change the URL structure of a page but still retain the benefits of backlinks, a 301 redirect will declare the new URL as the successor to the previous URL.
Netlify allows you to easily set up redirect and rewrite rules in the _redirects file added to the root of the public folder when you are running a website. Similarly, if you are deploying a project on Vercel, you can set up redirects in the vercel.json file located at the root of the directory as shown below. For Amazon S3 users, you can set up redirects as follows.
Another way to deal with duplicate content is to use the rel=canonical attribute in the link tag.
<link href="URL OF ORIGINAL PAGE" rel="canonical" />
There are two ways to use it. By using the code above, the search engine will point to the original canonical version of the page. This means that the one crawler you are currently accessing should be treated as a copy of the specified URL.
Alternatively, it can be used as a self-referential rel=canonical link to an existing page.
<link href="PAGE URL" rel="canonical" />
In either case, the canonical attribute ensures that the correct page or the preferred version of the page is indexed.
For example, Gatsby has a simple plugin called gatsby-plugin-canonical-urls that sets the base URL used for the website's canonical URL. If you are using Next JS, you can use a package called next-absolute-url or opt out of Next SEO, which is a plugin that makes SEO management easier in Next.js projects.
Hugo supports permalinks, aliases, and link normalization, and offers multiple options for handling both relative and absolute URLs. As described here, it is an absolute URL. One of the potential solutions for canonical URLs in Jekyll can be found here.
5-3 Structured Data
Search engines, including Google, use Schema.org structured data to better understand the content of pages and display it in rich search results.
While properly implementing structured data may not directly affect rankings, it can increase the likelihood of appearing in approximately 30 types of rich search results that utilize schema markup.
Creating properly structured data is very easy. For schemas suitable for your content, please refer to schema.org. You can also check the coding steps using Google's Structured Data Markup Helper.
Structured data is one way to provide detailed information about a webpage to Google (and other search engines), but the biggest challenge is deciding which type to use on the page. The best practice is to focus on using typically one top-level type per page.
The use of structured data is most beneficial for search queries where search results display not only titles and descriptions but also additional content, such as in e-commerce, recipes, and job listings. Let's take a look at this article from MOZ. It will help you understand which structured data is right for you.
There are two ways to handle structured data with Jamstack. Most headless CMSs provide tools for managing structured data on a per-page basis in the form of custom component definitions, so you can rest assured. Alternatively, you can also add schemas as part of the template you are using.
5-4 Crawl Budget
Crawl budget refers to how much attention search engines pay to your site. If you operate a large website with a significant number of pages, prioritizing what to crawl, when to crawl, and how many resources to allocate for crawling becomes very important, and this is managed through the crawl budget. If not handled properly, important pages may not be crawled and indexed.
If you are not operating a website with a considerable number of pages (consider more than 10,000 pages) or have recently added a new section with a large number of pages that need to be crawled, it is recommended to keep your crawl budget on autopilot.
However, it is good to know that there are several things you can do to maximize your site's crawl budget. Most of these involve improving website performance, limiting redirects and duplicate content, and setting up a good website structure and internal links, as already mentioned.
6. In a nutshell, Technical SEO
Today's SEO is a collective effort of developers, UX, products, and SEO specialists. It is about balancing potential audiences, search engines, and business goals and expectations. When done correctly, it is not just a strategic way to increase website traffic. It can also simultaneously improve UX, conversions, and accessibility.
Speed and performance are becoming increasingly important to both users and search engines, necessitating a reliable architecture that supports website performance.
Jamstack may be a new way to build websites, but it offers impressive advantages over traditional stacks, in addition to performance and SEO benefits. Among these, security and scalability are top-notch.
In Part 2, we will discuss content, on-page and off-page optimization.
Bejamas Service Introduction Materials
This is information about the latest web development method, Jamstack, and its developer, Bejamas.
Human Science collaborates with Bejamas to support improvements in manuals, FAQs, corporate websites, and more.

- What is Jamstack? What can be achieved?
- Technology Used by Bejamas
- Services offered by Bejamas
- Bejamas Collaboration Approach
- Client Testimonials
- Case Study