- 目次
-
- 1.PDF翻訳
- 2.PDF翻訳ツールにはどんなものがある?(主要8選)
- 2-1.DeepL
- 2-2.Google翻訳
- 2-3.Google翻訳アプリ
- 2-4.MTrans Team (エムトランス チーム)
- 2-5.MTrans for Office (エムトランス フォー オフィス)
- 2-6.Acrobat AIアシスタント
- 2-7.Adobe Express
- 2-8.T-4OO
- 3.PDF翻訳ツールの翻訳結果を比較!
- 3-1.翻訳精度
- 3-2.スキャンPDFのOCR精度
- 4.PDF翻訳がうまくできない理由とデメリット
- 4-1.PDFファイルが保護されており、翻訳ができない
- 4-2.レイアウトや表の崩れが生じる
- 4-3.意図しない改行で意味の通じない翻訳になってしまう
- 4-4.自動翻訳の処理容量が小さく、サイズの大きなファイルは一度に翻訳するのが難しい
- 4-5.情報漏洩のリスクがある
- 5.PDFの翻訳ツールに求められる条件は?
- 5-1.翻訳精度の高さとOCR機能の有無
- 5-2.レイアウトを維持したまま翻訳できること
- 5-3.大容量のPDFに対応できるか
- 5-4.セキュリティとプライバシーへの配慮
- 5-5.翻訳後の編集機能
- 6.まとめ
1. PDF翻訳
PDFファイルには、文章がテキストデータとして格納されているテキストベースのPDFと、文章が画像データとして格納されている画像ベースのPDFの2種類の形式があります。画像ベースのPDFは、コピー機でスキャンした書類であることが多いため、スキャンPDFとも呼ばれます。
Adobe Acrobat ReaderアプリでテキストベースのPDFを開くと、マウスカーソルを使って文章を選択できます。

スキャンPDFの場合は、文章を選択しようとすると、ページ全体が選択されてしまいます。

テキストベースのPDFを翻訳したい場合は、文章を選択してコピーし、自動翻訳サービスにペーストします。一方、スキャンPDFを翻訳したい場合は、PDFを見ながら人手で文章を打ち直さなければなりません。しかし、文章の分量が多いと非常に時間がかかり現実的ではありません。
そこで、文字を認識してテキストデータに変換するOCRと呼ばれる機能が必要になります。Windows 11の標準アプリであるSnipping Tool(スニッピング ツール)にはOCR機能が搭載されています。Snipping Toolを使って画面の任意の場所を画像としてキャプチャし、その後、ツールバーにある「テキスト アクション」ボタンをクリックすると、OCR機能を実行できます。
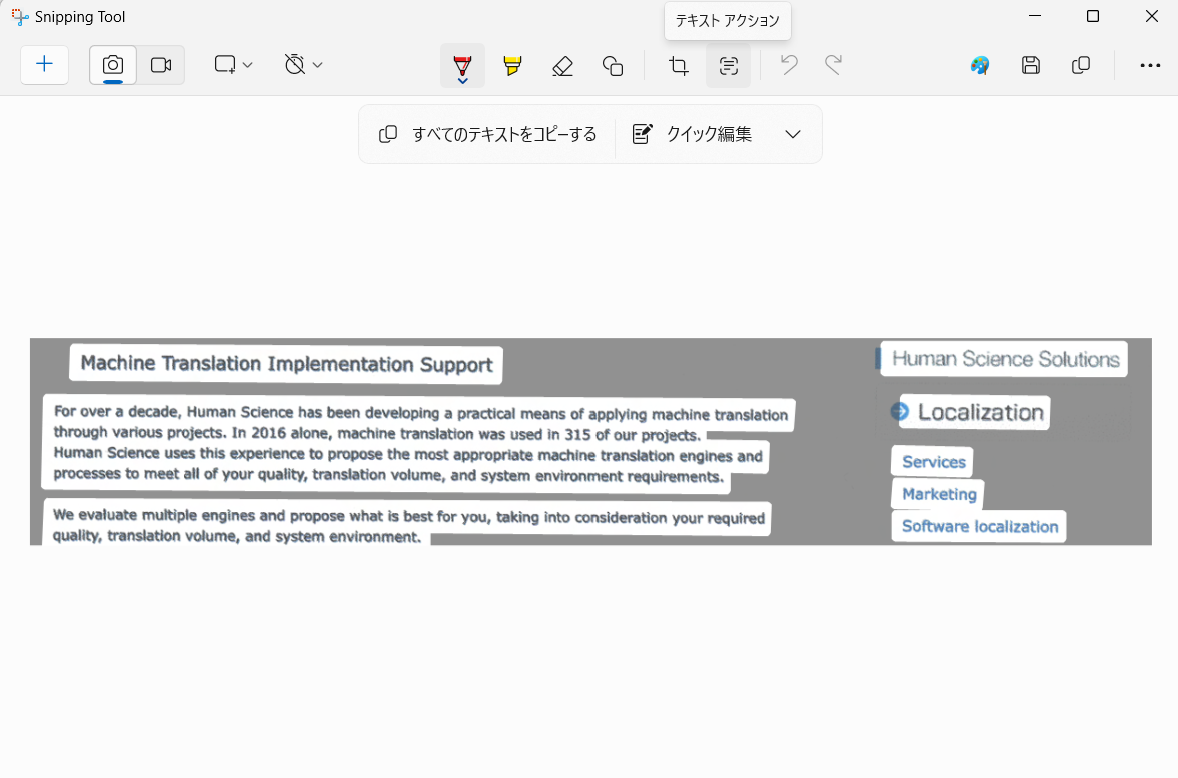
OCRが完了したら、任意の文章をマウスで選択することも、「すべてのテキストをコピーする」をクリックして全選択&コピーすることもできます。あとは、コピーした文章を自動翻訳サービスに貼り付ければ翻訳できます。
ただし、1画面に収まらないPDFの場合は、スクロール、画面キャプチャ、OCR実行、コピー&ペーストという手順を繰り返す必要があり、非常に手間になります。
また、テキストベースのPDFの場合もスキャンPDFの場合も、文章をコピーして翻訳した場合、PDFのレイアウトは保持されません。レイアウトを保持したままPDFを翻訳するには、PDFファイルをそのまま翻訳するPDF翻訳ツールが必要です。
2. PDF翻訳ツールにはどんなものがある?(主要8選)
代表的な自動翻訳サービスにDeepLやGoogle翻訳があります。いずれもPDFファイルを翻訳できますが、対応の程度は異なります。ここではそれらを含めた8つのツールを紹介します。
2-1. DeepL
DeepL にはファイル翻訳と呼ばれる機能が搭載されています。PDFファイルをアップロードして翻訳できます。テキストベースのPDFとスキャンPDFの両方に対応しています。レイアウトを保ったまま翻訳され、翻訳済みPDFをダウンロードできます。
DeepLの利用プランによって翻訳できるファイル数やファイルサイズが異なります。無料版ではファイル数は月に3個まで、ファイルサイズは5MBまでの制限があります。翻訳後のPDFファイルは編集できません。
有料版では、ファイル数がプランによって月に5~100個まで、ファイルサイズは10~30MBまでの制限があります。翻訳後のPDFファイルは編集可能です。Wordファイルとしてダウンロードすることもできます。
無料版を利用する場合は、入力したデータがDeepL社に二次利用される場合があるため注意が必要です。セキュリティの詳細については、以下のブログ記事をご覧ください。
また、無料版と有料版の違いについては、以下のブログ記事をご覧ください。
DeepLの無料版と有料版(DeepL Pro)の違いとは? ~料金、セキュリティ、文字数~
2-2. Google翻訳
ウェブページやChromeブラウザから利用できるGoogle翻訳にはドキュメント翻訳と呼ばれる機能が搭載されています。PDFファイルをアップロードして翻訳できます。テキストベースのPDFにのみ対応し、スキャンPDFには対応していません。テキストPDFはレイアウトを保ったまま翻訳され、翻訳後のPDFをダウンロードできます。翻訳後のPDFは編集できません。ファイルサイズの上限は10MBです。
2-3. Google翻訳アプリ
iPhoneやAndroid向けにGoogle翻訳アプリが提供されています。

Google翻訳アプリには「リアルタイム カメラ翻訳」と呼ばれる機能が搭載されています。アプリを起動して、スマートフォンのカメラを翻訳対象の資料に向けると、レイアウトを維持したまま自動翻訳することができます。たいへん便利ですが、前述のGoogle翻訳と同様にGoogle翻訳アプリでは翻訳文書の機密が保持されないため、業務で使用するには問題があります。
2-4. MTrans Team (エムトランス チーム)
弊社の自動翻訳製品のMTrans TeamにもPDF翻訳機能が搭載されています。PDFファイルをアップロードして翻訳できます。テキストベースのPDFとスキャンPDFの両方に対応しています。自動翻訳を行う翻訳エンジンとしてGoogle、Microsoft、NAVER Papago、OpenAI、Claudeから選択できます。レイアウトを保ったまま翻訳され、翻訳済みファイルは、編集可能なWordファイルとしてダウンロードできます。ファイルサイズの上限は45MBです。
2-5. MTrans for Office (エムトランス フォー オフィス)
弊社のもう一つの自動翻訳製品のMTrans for OfficeはOutlook、Word、Excel、PowerPointに自動翻訳機能を追加します。このうち、Windows版のMTrans for Office に、DeepLとGoogleを使ったPDF翻訳機能が搭載されており、テキストベースのPDFとスキャンPDFの両方に対応しています。レイアウトを保ったまま翻訳され、編集可能なPDFが保存されます。ファイルサイズの上限は、翻訳エンジンとしてDeepLを使う場合は30MB、Googleを使う場合は20MBです。
翻訳エンジンとしてGoogleを選択した場合、OCRと自動翻訳にGoogle Cloud Translation APIが利用されます。GoogleのOCR機能は長年スマートフォンのGoogle翻訳アプリで広く利用されており、技術的なノウハウが蓄積されているため、より高い精度で文字を認識できます。
DeepLとGoogleの両方でPDF翻訳に対応していますが、翻訳とOCRの精度は異なります。MTrans for Officeでは両サービスに対応しているため、それぞれのサービスを使ってPDFを翻訳、比較して、より良い精度のものを選択できます。
2-6. Acrobat AIアシスタント
Acrobat AIアシスタントは、生成AIベースの対話型エンジンを搭載しています。PDFファイルを開き、チャット形式で「日本語に翻訳して」と指示するだけで翻訳できます。単なる直訳だけでなく、要約を同時に行うことも可能なため、長文の文書内容も効率よく把握できます。スキャンしたPDFに対しても、AIアシスタントが自動でテキストを読み取って(OCR処理の後に)翻訳できます。ただし、翻訳できる分量に制限があるため、数ページを超えると文書の一部しか翻訳されません。また、翻訳結果はチャット画面に表示されるため、PDFのレイアウトを維持したまま翻訳する用途には向いていません。
2-7. Adobe Express
Adobe Expressは、デザインツールでありながらPDF翻訳機能を搭載しており、PDFのレイアウトやデザイン要素を維持したまま多言語に翻訳できます。翻訳後のテキストは、元のPDFとほぼそのままの見た目で新しいページとして複製されるため、カタログや提案書などのデザイン性を重視する文書の翻訳に特に適しています。翻訳後には、フォントや色、配置などのデザインを自由にカスタマイズして見栄えを整えることもできます。OCR機能は搭載されていないため、スキャンしたPDFの翻訳には対応していません。
2-8. T-4OO
T-4OOは、専門2000分野に対応する専門文書翻訳エンジンです。テキストベースのPDFとスキャンしたPDFの両方に対応しており、ファイルをドラッグ&ドロップするだけで翻訳できます。スキャンPDFを翻訳する際には、まずOCRが適用されますが、T-4OOではそのOCR結果を画面上で確認・修正できる機能があるため、文字化けなどの問題があっても正確に翻訳することが可能です。翻訳後も原文のレイアウトが保持され、専門文書を効率的かつ正確に翻訳できます。
3. PDF翻訳ツールの翻訳結果を比較!
ここまで紹介した8つのツールの特徴(料金、精度、安全性)を比較表にまとめました。
【PDFファイルを簡単かつ安全に翻訳するツールの比較】
| No. | サービス | 料金 | 精度 | 安全性 |
|---|---|---|---|---|
| 1 | DeepL | 無料または法人向けTeamプラン月額3,750円~ | 流暢さに優れる。クラシックモデルは訳抜けが目立つが、次世代モデルは改善された | 無料版は二次利用あり、有料版は二次利用なし |
| 2 | Google翻訳 | 無料 | 日常会話〜一般文書で十分な精度。専門分野では誤訳あり。 | 二次利用あり |
| 3 | Google翻訳アプリ | 無料 | 日常会話〜一般文書で十分な精度。専門分野では誤訳あり。OCRの精度が高い | 二次利用あり |
| 4 | MTrans Team | 初期費用10万円、月額1,371円(プラン、人数により変動) | 複数のエンジンの訳を比較可能。過去訳を蓄積することで使えば使うほど精度が向上 | 二次利用なし |
| 5 | MTrans for Office | 初期費用10万円、300名で1名月額660円(人数により変動) | 複数のエンジンの訳を比較可能 | 二次利用なし |
| 6 | Acrobat AIアシスタント | Adobe Acrobat Pro等のサブスク月額1,848円~+AIアドオン月額680円 | 翻訳専用サービスと比較すると精度、流暢さが劣る | 二次利用なし |
| 7 | Adobe Express | 月額1,180円 | 翻訳専用サービスと比較すると精度、流暢さが劣る | 二次利用なし |
| 8 | T-4OO | 翻訳分量に応じて異なる。例:初期費用+5名年間36万円 | 法務・医薬・化学・機械・IT等の専門分野で「最大95%精度」をうたう | 二次利用なし |
以下では、特に代表的なDeepLとGoogleの精度について詳しく見ていきます。
3-1. 翻訳精度
DeepLは、ネイティブのように流暢で自然な翻訳が特徴です。しかし、DeepLの課題として、長文を翻訳したときに語句が抜けたり、複数の文をまとめて翻訳したときに文が欠落したりすることがあるため、人間による確認が必須です。特に、訳文だけを読んで確認すると、その流暢さが原因で、訳の抜けを見逃す可能性が高いです。必ず、原文と訳文を照らし合わせて確認するようにしてください。
一方、Google翻訳の訳文は、DeepLと比較すると流暢さがやや劣る傾向があるものの、訳が抜けることは少ないです。一般的に、流暢さを優先する場合はDeepLを、正確さを優先する場合はGoogleを利用することをお勧めします。DeepLとGoogleの詳細な比較結果については、以下のブログ記事をご覧ください。
機械翻訳とは?メリット・デメリットから最新動向、「DeepL」と「Google翻訳」との比較まで解説!
DeepL の翻訳精度は?ビジネスメールでのGoogle、Microsoftとの比較結果
3-2. スキャンPDFのOCR精度
以下のようなスキャンPDFを用意して、DeepLとGoogleのOCR精度を比較しました。なお、Googleについては、ウェブページから利用する「Google翻訳」がスキャンPDFに対応していないため、MTrans for Officeを用いてGoogle Cloud Translation API経由でPDF翻訳を行いました。

画像はDeepLで翻訳した結果です。上部の見出し部分は翻訳できましたが、残りの部分は英語のままでした。また、英語の多くの部分が欠落するという結果となりました。スキャンPDFの画質が粗い場合や文字が小さい場合に、OCR精度が下がる傾向があります。
一方、Googleでは、大部分の英語テキストが正しく認識され、翻訳されました。しかし、図表の英語が間違って翻訳されたほか、縦書きの訳文のレイアウトが崩れています。図表の翻訳とレイアウトに課題が残る結果となりました。
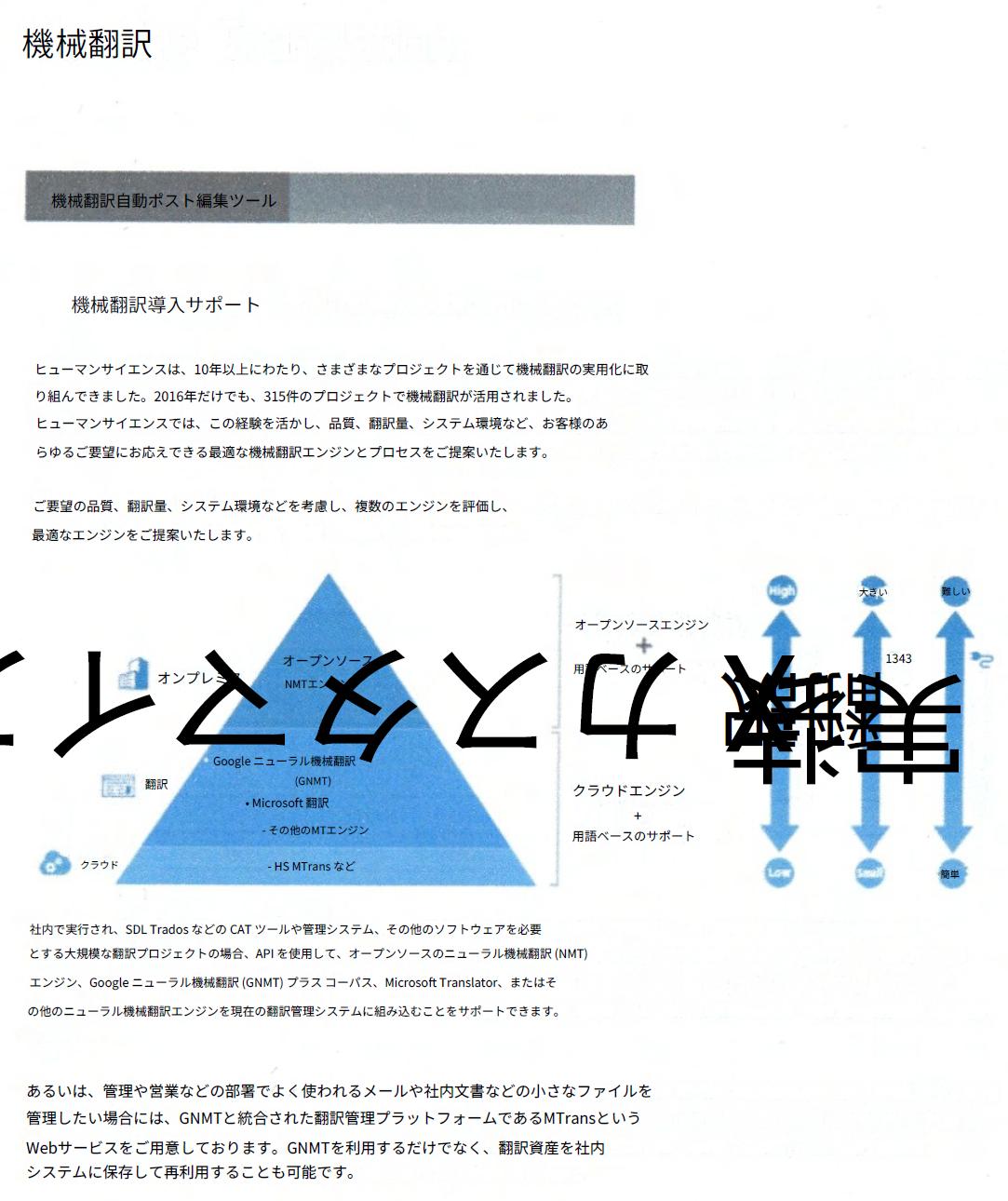
OCRを伴うスキャンPDFを翻訳する場合は、課題は残るものの、一般的にはGoogleをAPI経由で利用することをお勧めします。
4. PDF翻訳がうまくできない理由とデメリット
4-1. PDFファイルが保護されており、翻訳ができない
パスワード保護されたPDFファイルは直接翻訳できません。パスワードを解除し、パスワード保護されていないPDFファイルを用意する必要があります。パスワードが解除できない場合でも印刷が許可されていれば、Windowsの「Microsoft PDF 印刷」を使って新しいPDFファイルとして保存して、このPDFファイルを翻訳できます。
4-2. レイアウトや表の崩れが生じる
PDFを自動翻訳すると、レイアウトや表が崩れてしまう場合があります。DeepLの有料版、MTrans Team、MTrans for Officeで翻訳した場合、翻訳後に出力されるPDFまたはWordファイルをWordアプリに読み込めるため、手作業で修正できます。
4-3. 意図しない改行で意味の通じない翻訳になってしまう
一文が途中で分割されて複数の文として認識される場合があります。テキストベースのPDFでもスキャンPDFでも、MTrans Teamであれば、自動翻訳後に原文を編集できるため、原文の複数の文を一文にまとめてから再度、自動翻訳することができます。
4-4. 自動翻訳の処理容量が小さく、サイズの大きなファイルは一度に翻訳するのが難しい
スキャンPDFのファイルサイズは大きくなることが多いため、自動翻訳サービスのファイルサイズの上限が問題になる場合があります。上限を超える場合は、ファイルを分割するか、またはAdobeが提供しているPDFファイルの圧縮サービス(https://acrobat.adobe.com/link/acrobat/compress-pdf)を利用できます。なお、PDFを圧縮する際には、文字が潰れないように低い圧縮レベル(最高画質)を選択すると、文字の認識精度が下がりにくくなります。
4-5. 情報漏洩のリスクがある
無料版のDeepLやGoogle翻訳を利用すると、入力したデータが別の目的に流用されるおそれがあります。機密情報を翻訳する場合は、無料の自動翻訳サービスではなく、セキュリティが確保された有料サービスを利用する必要があります。DeepLのセキュリティについて詳しくは、「DeepL翻訳で機密は保持される?セキュリティは?」をご覧ください。
5. PDFの翻訳ツールに求められる条件は?
5-1. 翻訳精度の高さとOCR機能の有無
PDFファイルを正しく翻訳するためには、翻訳エンジンの性能が高く、かつスキャンPDFに対するOCR機能が充実していることが求められます。DeepLとGoogleの両方の翻訳エンジンに対応している製品であれば、文書の内容や用途に応じて自由にエンジンを切り替えられるため便利です。また、OCRの精度が高いほど、スキャンPDFのテキストが正確に認識され、翻訳の抜けや誤認識を抑えられます。
5-2. レイアウトを維持したまま翻訳できること
PDFを翻訳する場合、レイアウトを保持するかどうかは非常に重要です。レイアウトを維持しなければ、図表や画像を含む資料の場合、翻訳後に修正作業が多く発生し、作業効率が落ちてしまいます。レイアウトを維持したままPDFやWord形式などで出力できる機能があると、翻訳した後の編集が容易になります。
5-3. 大容量のPDFに対応できるか
ファイルサイズの大きいPDFを翻訳する場合、翻訳ツールの上限を超えてしまうことがあります。特にスキャンPDFはどうしてもファイルサイズが大きくなる傾向があります。複数の翻訳エンジンが利用できる場合でも、ファイルサイズやページ数の制限は異なるため、事前にチェックする必要があります。ファイルを分割、圧縮する手間をかけずに翻訳できるかどうかも重要なポイントです。
5-4. セキュリティとプライバシーへの配慮
機密情報を含むPDFを翻訳する場合、データの取り扱いには細心の注意を払わなければなりません。無料版の自動翻訳サービスは、アップロードした情報がサービス改善のために二次利用される場合があるため、ビジネスでの利用は避けるべきです。翻訳ツールを導入する際は、どのようなセキュリティ対策が実施されているか、プライバシーポリシーが明確かどうかを確認しましょう。
5-5. 翻訳後の編集機能
自動翻訳は便利ですが、必ずしも完璧な訳文が得られるわけではありません。翻訳の抜けや誤訳が発生した場合、翻訳されたワードファイルやPDFファイルを容易に修正できる機能があると作業効率が大幅に向上します。特に、原文と訳文を並べて比較・修正ができるツールであれば、抜け漏れを見つけやすく、訳の正確性が高まります。
6. まとめ
本記事では、PDF翻訳の課題であるOCR、レイアウト維持、機密性を踏まえ、8つの主要ツールの特徴を説明しました。無料で手軽に使えるGoogle翻訳は機密性に難があるため、業務で使用する場合はその他の有償ツールを利用する必要があります。レイアウトを重視するならAdobe Express、社内利用で機密性・生産性を重視するなら複数エンジンに対応したMTrans Team/MTrans for Officeを推奨します。用途(機密性、レイアウト、OCR、専門性、コスト)を明確にし、要件に合うサービスを選定することが重要です。
ヒューマンサイエンスは、テキストベースのPDFとスキャンPDFの両方に対応し、DeepL、Google、Microsoft、OpenAIの翻訳エンジンを活用できる自動翻訳ソフト「MTrans for Office」を提供しています。OpenAIは、翻訳だけでなく、プロンプト次第で文章の生成や書き換え、文章校正も行うことができ、業務効率化や多言語対応をサポートします。MTrans for Officeは、14日間の無料トライアルも受け付けています。お気軽にお問い合わせください。
MTrans for Officeの特長
① 翻訳できるファイル数、用語集に制限はなく定額制
② Office製品からワンクリックで翻訳できる!
③ API接続でセキュリティ面も安心
・さらに強化したいお客様にはSSO、IP制限などもご提供
④ 日本企業による日本語でのサポート
・セキュリティチェックシートへの対応も可能
・銀行振込でのお支払いが利用可能
Officeかんたん翻訳ソフトMTrans for Officeとは