 テキストアノテーション
テキストアノテーション 音声アノテーション
音声アノテーション 画像・動画アノテーション
画像・動画アノテーション 生成AI、LLM、RAGデータ構造化
生成AI、LLM、RAGデータ構造化
 AIモデル開発
AIモデル開発 内製化支援
内製化支援 医療業界向け
医療業界向け 自動車業界向け
自動車業界向け IT業界向け
IT業界向け 製造業向け
製造業向け

最近、多くの企業が生成AIやLLMを導入し始めていますが、「翻訳結果の品質が不安定」「学習データの精度をどう担保するか」といった課題に直面するケースが少なくありません。
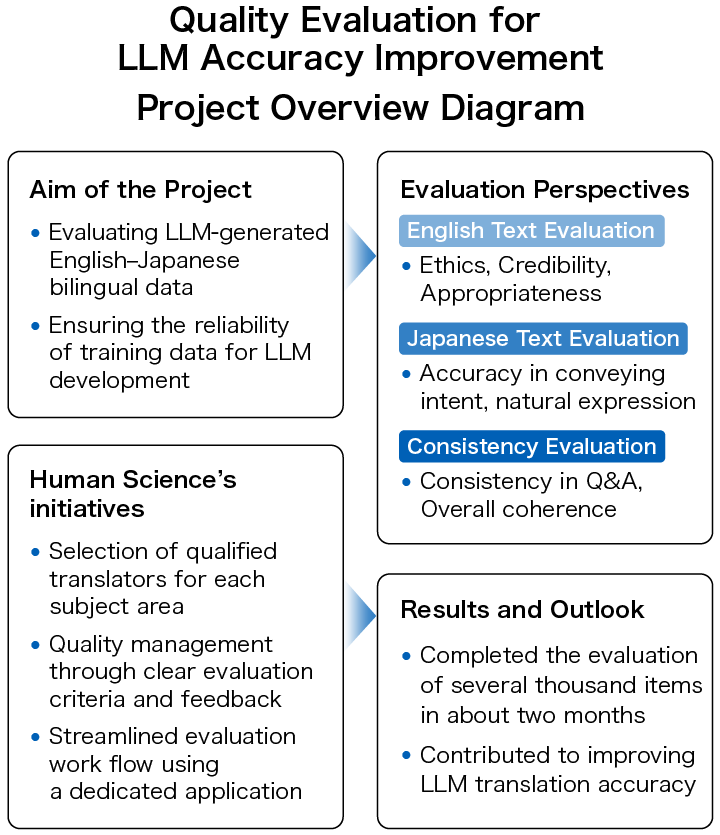
私たちヒューマンサイエンスも、「LLMの翻訳精度を高めたい」というお客様のご要望から、英日バイリンガルデータの品質を人の手で丁寧に評価するプロジェクトに対応しています。この記事では、そのプロジェクトの流れと成果をご紹介します。

- 目次
1. プロジェクト概要:LLM翻訳精度向上のためのバイリンガルデータ評価
お客様が収集したさまざまな分野(医療、科学、金融、政治、スポーツ、経済、文化など)の英文と、それに対応する和文(LLMが生成した日本語訳)のデータセットをご提供いただきます。ヒューマンサイエンスでは英文と和文のバイリンガルデータを対象に、一定の品質レベルに達しているかを判断する「データ評価」を行います。
1-1. 英日バイリンガルデータをどう評価する?
評価対象は、機械的に収集された英文と、LLMが生成した和訳からなるバイリンガルデータです。このバイリンガルデータの精度はどのように評価すればよいでしょうか。評価の観点についてご紹介します。
・英文評価-データの適格性をどう判断する?
評価では、まず英文が学習データとしてふさわしいかどうかを確認します。例えば倫理的に適切かという観点で、差別的な内容、または事実に反する嘘やデマの情報が含まれる場合は、英文の時点で不適格として「合格基準に達していない」と評価します。
・和文評価-正確さと自然さをどう判断する?
次に、和文の品質が合格基準に達しているかを、いくつかの評価項目に基づいて英文に照らして評価していきます。評価の基準は、英文の意図が伝わるか、日本語表現が自然かなどの数項目です。日本語表現が自然で読みやすくても、英文の意図をくみ取れていなかったり、誤解を生む表現になっていたりする場合には評価を落とします。
・整合性評価-LLM特有の課題とは?
バイリンガルデータは、本文とそれに関連する質疑応答で構成されており、和文の正確さ・読みやすさに加え、質疑応答の内容が本文に即しているか、質疑応答自体が成立しているかという文章の整合性についても評価の対象とします。LLMの特徴として、逐語訳的に和文を作成するだけではなく、内容を要約して言い換えたり、追加の情報を付け加えたりすることもあります。そのため、言葉の置き換えを確認するだけではなく、英文が意図した内容をよく理解して評価する必要があります。


2. 評価精度を高める仕組み―ヒューマンサイエンスの工夫
・分野別に最適な評価者の選定
評価対象は、医療、科学、金融といった専門的な内容から、一般的なニュース記事まで幅広い分野にわたっていたため、ヒューマンサイエンスでは、翻訳者の中から分野ごとに最適なメンバーを選定します。
バイリンガルデータの評価は単に英語が日本語に置き換えられているかを見るだけではなく、英文の意図を正しく伝えられているか?日本語の読みやすさが一定レベルに達しているか?という翻訳品質をぶれない基準で見極める判断力が求められます。長年の実務翻訳で経験を積んだヒューマンサイエンスの翻訳者が、これまでの知見を活かして精度の高い評価を行います。
・品質を守るための評価基準とフィードバック体制
評価基準を一定に保つために、お客様とヒューマンサイエンスで品質レベルの確認を緊密に行い、作業者に共有します。
実際に評価作業を開始してみると、依頼の段階ではお客様の方でも想定していなかったようなイレギュラーなケースがでてきます。特にLLMが生成したバイリンガルデータでは、人が翻訳した和文では発生しないような不備も散見されます。例えば和文に他の言語や文字化けが混ざっていたり、誤訳ではないが全体で用語にばらつきがあり文意を損なっていたりすることがあります。これらのケースについて、それぞれスコアリングの基準をどこに設定するかを明確にしていく必要があります。この点はお客様にもご協力いただき、メールやミーティングでのやり取りで、細かい点についても基準をクリアにしていきます。
なお作業者には一定の基準で評価を行えるようになるまで、こまめにフィードバックを行います。また最終チェック担当を置いて提出前のデータチェックを実施することで、複数のリソースを投入して集中的に作業を進行させる場合でも、評価基準のバラつきを抑え、品質を安定させることができます。
・専用アプリで効率アップ!技術チームのサポート
あるプロジェクトでは、お客様が準備される入力データはCSV形式、ヒューマンサイエンスから納品する出力データはJSON形式をご希望でした。CSV形式で入力されるバイリンガルデータに対して、複数の評価項目とそのスコア、必要であればコメントを付与し、JSON形式で出力するという流れです。
お客様の方で専用の評価プラットフォームをお持ちではない場合は、ヒューマンサイエンスの技術チームが専用の「評価アプリ」を開発します。画面上に英文と和文が並列に表示され、同じ画面上で評価項目のスコア入力を完結できるようになります。評価担当者からのフィードバックも参考に、試行錯誤して何度かアプリをアップデートし、評価しやすい、直感的にわかりやすいUIを実現します。専用アプリを使用することで、評価作業の効率化と誤入力・入力漏れの防止につなげることができます。
プラットフォームをお持ちでないお客様でも、ヒューマンサイエンスでは柔軟なツール開発・運用支援が可能です。まずはお気軽にご相談ください。


3. 成果と今後の展望―LLM精度向上に貢献
バイリンガルデータが数千件のプロジェクトでは、約2か月間で評価しました。限られた期間と予算の中で、評価作業をスムーズに完了し、LLMの精度向上のための有用なデータを提供することができます。今後も、分野に応じた専門性と柔軟な技術対応により、より大規模な評価案件にも対応してまいります。
4. まとめ:LLM開発における作業の依頼はヒューマンサイエンスへ
教師データ作成数4,800万件の豊富な実績
ヒューマンサイエンスでは自然言語処理に始まり、医療支援、自動車、IT、製造や建築など多岐にわたる業界のAIモデル開発プロジェクトに参画しています。これまでGAFAMをはじめとする多くの企業様との直接のお取引により、総数4,800万件以上の高品質な教師データをご提供してきました。数名規模のプロジェクトからアノテーター150名体制の長期大型案件まで、業種を問わず様々な教師データ作成やデータラベリング、データの構造化に対応しています。
クラウドソーシングを利用しないリソース管理
ヒューマンサイエンスではクラウドソーシングは利用せず、当社が直接契約した作業担当者でプロジェクトを進行します。各メンバーの実務経験や、これまでの参加プロジェクトでの評価をしっかりと把握した上で、最大限のパフォーマンスを発揮できるチームを編成しています。
キュレーション・アノテーションのみならず生成系AI LLMデータセット作成・構造化にも対応
データ整理ためのラベリングや識別系AIのアノテーションのみでなく、生成系AI・LLM RAG構築のためのドキュメントデータの構造化にも対応します。創業当初から主な事業・サービスとしてマニュアル制作を行い、様々なドキュメントの構造を熟知している当社ならではのノウハウを活かした最適なソリューションを提供いたします。
自社内にセキュリティルームを完備
ヒューマンサイエンスでは、新宿オフィス内にISMSの基準をクリアしたセキュリティルームを完備しています。そのため、守秘性の高いデータを扱うプロジェクトであってもセキュリティを担保することが可能です。当社ではどのプロジェクトでも機密性の確保は非常に重要と捉えています。リモートのプロジェクトであっても、ハード面の対策のみならず、作業担当者にはセキュリティ教育を継続して実施するなど、当社の情報セキュリティ管理体制はお客様より高いご評価をいただいております。

































































































