 テキストアノテーション
テキストアノテーション 音声アノテーション
音声アノテーション 画像・動画アノテーション
画像・動画アノテーション 生成AI、LLM、RAGデータ構造化
生成AI、LLM、RAGデータ構造化
 AIモデル開発
AIモデル開発 内製化支援
内製化支援 医療業界向け
医療業界向け 自動車業界向け
自動車業界向け IT業界向け
IT業界向け 製造業向け
製造業向け

AIの精度向上のためには機械学習が必要です。そのために利用されるのが教師データです。ここでは効果的な機械学習のための教師データとはどのようなものかについてお話していきます。
- 目次
-
- 1. 教師データとは何か?
- 1-1. AI、機械学習、教師データ、アノテーションの関係は?
- 1-2. AIの学習に欠かせない教師データ
- 1-3. 時間のかかるアノテーション
- 1-4. どのくらいの量が必要なのか
- 1-5. 教師データと学習データの違いとは?
- 1-6. 機械学習の3つのアプローチ
- 2. 教師データの品質が重要視されている理由とは?
- 2-1. 高品質な教師データとは
- 2-2. なぜ教師データの品質が重要視されるのか?
- 3. 教師データの作り方の手順
- 3-1. 目的の明確化
- 3-2. 必要なアノテーション要件の定義
- 3-3. データ収集
- 3-4. アノテーションの実施
- 4. 教師データの生産で重要な3つのポイント
- 4-1. 作業ルールの統一
- 4-2. アノテーションに適したマネジメント体制
- 4-3. セキュリティレベルの確保
- 5. ヒューマンサイエンスの教師データ作成、LLM RAGデータ構造化代行サービス
1. 教師データとは何か?

1-1. AI、機械学習、教師データ、アノテーションの関係は?
まずAI (人工知能) が働く仕組みについて整理します。AIが仕事を覚える構造そのものは人間と同じです。AIもトレーニングを重ねることで判断能力や処理スピードが向上します。このトレーニングのことを機械学習またはML (Machine Learning) と呼びます。AIが機械学習を行う際に利用するデータが教師データです。よく目にするアノテーションという言葉は、教師データを作る作業のことです。
ここでいったん用語を整理しておきましょう。
AI:人工知能そのものを指します。
機械学習:AIが精度を上げるためのトレーニングです。
教師データ:機械学習に利用するデータです。
アノテーション:教師データを作る作業です。
AI開発の工程でのアノテーションの位置づけはこのようになります。

1-2. AIの学習に欠かせない教師データ
教師データとはその名の通り、AIが学習するときに教師の役割を果たすデータです。
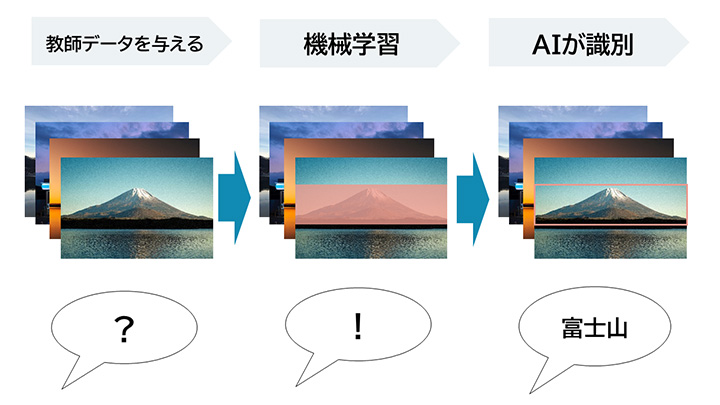
例えば、AIに「富士山」の写真を見せて「これは何?」という質問と、「これは富士山です」という答えの両方を人間が教えます。富士山の写真を大量に何度も見せます。するとAIがどんどん「富士山」を覚えていくので、写真を見せて「これは何?」と聞いたときの「これは富士山です」「これは富士山ではありません」という答えの正解率が上がっていきます。ここでAIに見せる、問題と解答を情報として付加したデータのことを教師データと呼びます。人間と同じでAIも学習すればするほど正解率は上がります。AIの精度をより高めるには、必要十分な量の教師データを使って繰り返し学習させることが必要です。
次に教師データを作成するアノテーション作業について解説します。
1-3. 時間のかかるアノテーション
アノテーションは手作業によって行われるため、作業者には正確な知識と判断力に加えて、相当な根気強さも求められます。AIにできることが増えていく背景には、この地道なプロセスが必ず存在します。
画像データを使ったアノテーションでは、アノテーターが画像内の特定の領域を手作業で指定して情報を付加します。上の富士山のような例では、画像を1枚1枚目視で確認して、富士山が写っている領域だけを正確に選択するという作業が行われます。
1-4. どのくらいの量が必要なのか
必要な教師データの量はどれくらいなのでしょうか。その答えはプロジェクトの目的や目標とする精度によって変化します。手持ちのデータで実際にAIに学習させてみて、その量で課題を解決できるか、それともまだ学習が足りないかを検証します。足りないようであれば教師データを追加して学習を継続します。うまくいかないようであれば教師データの作成ルールから見直すこともあります。 教師データについては量と品質の両面から考える必要があります。
1-5. 教師データと学習データの違いとは?
ここでは教師データと学習データの違いについて解説します。
:教師データ
アノテーションによってラベル付されたデータのセットが教師データです。このデータを元にAIが認識するべき対象を学習します。ラベル付されたデータのみを学習しても、ラベルのないデータをうまく認識できるかどうかは教師データだけでは評価できません。
:学習データ
学習データは、AIが学習に使うデータ全体のセットを指します。教師データ以外のラベルのないデータも含みます。教師データで認識するべき対象を学習したAIが、ラベルなしデータを通して認識精度を高めます。また、学習の手法によっては、教師データを持たない学習データセットもあります。
1-6. 機械学習の3つのアプローチ
ここでは機械学習で用いられる学習方法について代表的な3つのアプローチについて解説します。
1. 教師あり学習
教師あり学習とは、正解のラベルを付与した教師データを含んだ学習データを用いる手法です。AI開発で主に使われる手法で、教師データを作成するためのアノテーション作業が必要となります。物体検出には教師あり学習が使われることが一般的です。
2. 教師なし学習
教師データを含まない学習データを用いる手法です。データの中のパターンを見つけ出し、そのパターンに応じてデータを分類する手法で、異常検出などを目的としたAIの学習に多く使われます。
3. 強化学習
強化学習とは、システムが自身で試行錯誤を繰り返し、最適解を見つける学習方法です。ルールが明確に定義された課題で最適解を求められる場合に使われる手法です。ロボット制御やチェスなどのゲームで勝つためのAIが身近な例としてあります。
2. 教師データの品質が重要視されている理由とは?
2-1. 高品質な教師データとは
教師データの品質はAIの精度に大きな影響を与えます。高品質な教師データは、偏りのない素材とバラつきのないアノテーションの両方が揃って成立します。先に述べた例のように富士山を学習させるのであれば、同じような写真ばかりではなく、撮影場所や時間帯の違う様々な富士山の写真を偏りなく用意する必要があります。作業面では明確なルールを策定して、アノテーター全員が同じ判断基準で作業することが重要です。
ここで言う高品質な教師データとは、必ずしもアノテーションの精度が高いこと(例:対象物の輪郭に沿って可能な限り滑らかにセグメンテーションする、対象物にバウンディングボックスを1ピクセル内に収まるようにピッタリ合わせる、など)を意味するわけではありません。重要なのは、必要な要件が定義された作業指示書や仕様書に基づいてアノテーションが適切に行われているかどうかです。たとえば、車をバウンディングボックスで囲むタスクにおいて、仕様書に「多少の余白を許容する」と記載されていれば、対象に対してぴったり囲まなくても許容範囲に収まっていれば、そのデータは高品質であると言えます。
高品質とは、「仕様に合致していること」であり、「精度が高いこと」とは必ずしもイコールではありません。必要以上に精度を高めようとすれば、工数もかかってしまいます。そうなれば、品質のみならず、開発スケジュールに遅れが出るなどの影響も起こり得ます。
2-2. なぜ教師データの品質が重要視されるのか
AI開発の目的に沿った要件定義ができても、教師データの品質が低くてはAIの学習はうまくいきません。もし品質の低い教師データでAIが学習をすると、開発の目的にあった精度を得られないでしょう。そうすると再度アノテーションが必要になります。その際には同じアノテーターをアサインできないことも多く、アノテーターの再教育が必要にもなります。またデータの再作成のみでなく、それにまつわる付帯作業も追加になり、作業コストの増大ばかりでなく、プロジェクトの遅延が発生する可能性もあります。もし教師データが最初から高品質であれば、目的にあったAIが開発できるとともに、コストを最小限に抑え、開発サイクルを高速で回すことが可能になります。
次に、教師データの作り方について解説いたします。
3. 教師データの作り方の手順
AIの開発において、教師データの質はモデルの性能を大きく左右します。教師データを効率的かつ高品質に作成するには、いくつかのステップを踏み、計画的に進めることが重要です。以下に、教師データ作成の基本的な流れを4つのステップに分けてご説明いたします。
3-1. 目的の明確化
まず行うべきは、AIモデルで何を実現したいのかという目的を明確にすることです。例えば、車の画像認識を行う場合「車種の識別」を目指すのか、「車の有無の判定」が目的なのかによって、必要なデータやアノテーションの方法(画像分類・バウンディングボックスなど)が大きく変わります。この段階で目的をはっきりさせておくことで、その後の工程をブレずに進めることができます。
3-2. 必要なアノテーション要件の定義
目的が明確になったら、次はそれを実現するために必要なアノテーションの要件を定義します。どのアノテーション手法を用いるか、どんな属性やラベルが必要か、どの粒度まで作業を行うべきかといった内容を、仕様書や作業マニュアルとしてまとめます。
あらかじめ方針を明確にしておくことで、品質のばらつきや手戻りを防ぎ、スムーズな運用につながります。
3-3. データ収集
定義した要件に沿って、実際に使用するデータを集めます。収集方法にはさまざまな選択肢があります。
社内データの活用:既に保有しているデータを利用
オープンデータセット:公開されているデータセットを活用
新たなデータ収集:撮影や録音など、自前でデータを取得
データセットの購入:必要に応じて外部から購入
さらに、少ないデータしか用意できない場合は、データオーグメンテーション(Data Augmentation) を活用し、画像の反転や加工などでバリエーションを増やすことも有効です。学習に必要な量や質、コストや工数のバランスを考慮しながら、最適な方法を選択しましょう。
3-4. アノテーションの実施
データがそろったら、アノテーション作業に必要な前処理を行います。たとえば、画像形式の統一(例:JPEG形式に揃える)、ファイル名へのルール付け(連番や日付の付与)などです。また、作業に適したアノテーションツールの選定も重要なポイントです。
作業者を確保し、作業マニュアルの共有や説明を行ったうえで、アノテーション作業を開始します。作業が進む中では、進捗の管理や、作業中に発生する質問への対応、アノテーション結果のチェックといった品質管理が求められます。こうした運用を適切に行うことで、教師データ全体の精度と一貫性を担保することができます。
【関連リンク】
>教師データの品質を担保、向上させるには?実践方法を解説!
4. 教師データの生産で重要な3つのポイント

4-1. 作業ルールの統一
教師データの品質がバラバラだとAIは学習できません。人間と同じで、複数の先生からそれぞれ違うことを教えられると誰の言うことを聞けばよいのかわからなくなってしまいます。そうならないために、アノテーションのプロジェクトでは実作業の開始前に具体的な作業マニュアルを作成してチーム全員で共有することが重要です。難易度の高いプロジェクトでは最初にトライアル期間を設けて、テストにパスできたアノテーターだけでチームを編成することもあります。
4-2. アノテーションに適したマネジメント体制
アノテーションの作業には相当の注意深さや根気強さが必要です。さらに作業マニュアルの正しい理解やタグ付けを行う対象への知識や洞察力も要求されます。リソース面では作業を担当するアノテーターだけではなく、成果物を確認するチェッカーや教育を行うトレーナー、全体を統括管理するプロジェクトマネージャーの役割が必要です。プロジェクトの特性に合わせて効果的なマネジメント体制を構築することが、品質と生産性の確保につながります。
4-3. セキュリティレベルの確保
アノテーションでは守秘性の高いデータや個人情報が含まれるデータを扱うこともあります。そのためアノテーターへのセキュリティ教育は重要です。同時に作業環境の構築や使用ツールの選定においても十分なセキュリティ対策をとる必要があります。アノテーションのプロジェクトを外部の代行サービスに委託するときは、その外注先のセキュリティ対応のレベルを十分に確認しなくてはなりません。
5. ヒューマンサイエンスの教師データ作成、LLM RAGデータ構造化代行サービス
教師データ作成数4,800万件の豊富な実績
ヒューマンサイエンスでは自然言語処理に始まり、医療支援、自動車、IT、製造や建築など多岐にわたる業界のAIモデル開発プロジェクトに参画しています。これまでGAFAMをはじめとする多くの企業様との直接のお取引により、総数4,800万件以上の高品質な教師データをご提供してきました。数名規模のプロジェクトからアノテーター150名体制の長期大型案件まで、業種を問わず様々な教師データ作成やデータラベリング、データの構造化に対応しています。
クラウドソーシングを利用しないリソース管理
ヒューマンサイエンスではクラウドソーシングは利用せず、当社が直接契約した作業担当者でプロジェクトを進行します。各メンバーの実務経験や、これまでの参加プロジェクトでの評価をしっかりと把握した上で、最大限のパフォーマンスを発揮できるチームを編成しています。
教師データ作成のみならず生成系AI LLMデータセット作成・構造化にも対応
データ整理ためのラベリングや識別系AIの教師データ作成のみでなく、生成系AI・LLM RAG構築のためのドキュメントデータの構造化にも対応します。創業当初から主な事業・サービスとしてマニュアル制作を行い、様々なドキュメントの構造を熟知している当社ならではのノウハウを活かした最適なソリューションを提供いたします。
自社内にセキュリティルームを完備
ヒューマンサイエンスでは、新宿オフィス内にISMSの基準をクリアしたセキュリティルームを完備しています。そのため、守秘性の高いデータを扱うプロジェクトであってもセキュリティを担保することが可能です。当社ではどのプロジェクトでも機密性の確保は非常に重要と捉えています。リモートのプロジェクトであっても、ハード面の対策のみならず、作業担当者にはセキュリティ教育を継続して実施するなど、当社の情報セキュリティ管理体制はお客様より高いご評価をいただいております。

































































































