テキストアノテーション
テキストアノテーション 音声アノテーション
音声アノテーション 画像・動画アノテーション
画像・動画アノテーション 生成AI、LLM、RAGデータ構造化
生成AI、LLM、RAGデータ構造化
 AIモデル開発
AIモデル開発 内製化支援
内製化支援 医療業界向け
医療業界向け 自動車業界向け
自動車業界向け IT業界向け
IT業界向け 製造業向け
製造業向け

- 目次
1. はじめに
近年、ChatGPTをはじめとする大規模言語モデル(LLM: Large Language Model)の活用領域は飛躍的に広がっています。その精度を支えているものの1つが多様かつ大量の高品質な言語のデータセットと言えます。
こうした背景のもと、ヒューマンサイエンスではLLM開発用のバイリンガルデータセットの作成に対応しています。この記事では、データセットをどのように作成するのか、直面しうる課題とその対応策などをご紹介します。LLM開発のためのバイリンガルデータ作成について疑問をお持ちの方のヒントとなれば幸いです。
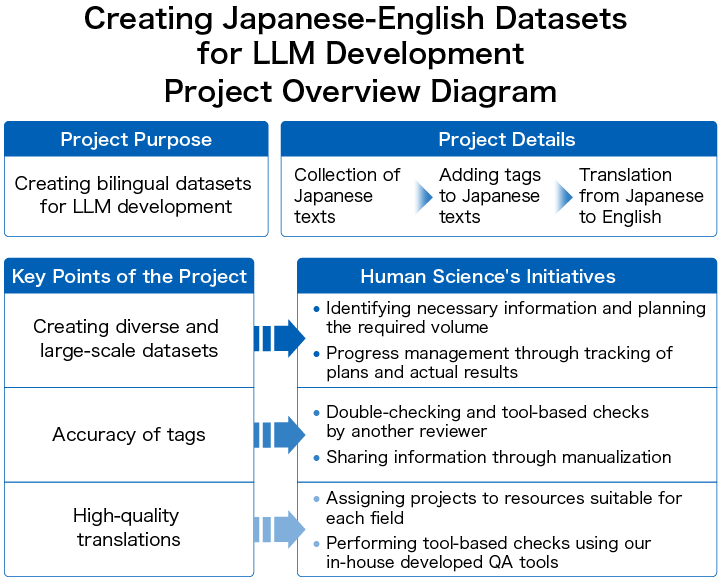
2. プロジェクト例:LLM開発用の日英データセット作成
プロジェクトの目的はお客様が自社で開発しているLLM用のデータセットを作成することです。このようなデータセットは、和文、その和文に対応する同じ内容の英文、およびタグ(和文に含まれる内容をタグとした情報)などで構成されます。1文を1つの単位とし、多数のデータを作成します。
このデータセットを作成するにあたり、主に以下のような作業があります。
・和文の収集
まずは和文の収集や作成を行います。IT、医療、金融、特許、日常会話といった幅広い分野の和文を対象とします。
・和文に対するタグの追加
対象の和文にどういった情報が含まれているかを説明するためにタグを付けます。
例えば以下の一文があるとします。
「株式ヒューマンサイエンスは1985年に設立され、本社は東京にあります。」
この一文には「組織名」(株式ヒューマンサイエンス)、「日付」(1985年)、「地名」(東京)といった情報が含まれるので、「組織名」「日付」「地名」のタグを付けるということを行います。案件によって必要な情報は様々だと思いますが、こうした形で対応するタグを付けます。
・和文から英文への翻訳
和文から英文へ人の手で翻訳を行い、和文と英文のバイリンガルデータを作成します。


3. LLM開発用データセットの作成における3つのポイント
次に、LLM開発用データセットの作成における重要なポイント、およびそのポイントに対してどのように対応するかについてご紹介します。
3-1. 多様かつ大量のデータセットの作成
LLM開発では、モデルに学習させるために大量のデータセットが求められます。言語は非常に多様であり、語彙や表現、話し言葉と書き言葉、文体、敬語の使い方など、幅広い特徴を持っています。そのため少量のデータセットでは、この多様性を網羅することができず、汎用性が失われる可能性があります。
また、少量のデータの場合、特定の話者や文体、内容に偏ることになります。大量のデータセットを用いることで、この偏りを相対的に改善し、より中立的なモデルにすることができます。
・和文データセットの作成
まず和文の収集について、収集を無計画に行うと一部の分野や媒体に偏ることがあります。そのため、最初に分野、媒体、場面、話者、必要な情報といった項目ごとに必要数を決めて計画し、計画と実績を都度比較してトラッキングを行うことが重要です。そうすることで、計画と比べて収集数にずれが生じている項目があった場合は、適宜調整を行い、バランスよくデータの収集・作成を進めることができます。
また、ヒューマンサイエンスには翻訳者・レビューアに限らず、厳しいトライアルを合格したアノテーターも多数登録されています。さらに自社内の開発チームと協力し、案件独自の補助ツールを開発することも可能です。そのためお客様の環境では人的・時間的コストが大きいような作業も、品質・技術面でご安心いただける体制で対応が可能です。
3-2. タグの正確性
LLM開発用のデータセット作成で行うタグ付けは、正確性が重要となります。例えば以下の一文があるとします。
「1月分の給与」
この一文にある「1月」は読み方により2つの意味が考えられます。「いちがつ」であればカレンダー上の1番目の月である1月を意味し日付の単位になりますが、「ひとつき」であれば1か月間という量や数を示す助数詞にもなります。
このように言語はコンテキストにより多義的ではありますが、情報をタグとして付けることで文の構造や文脈などを明示することができます。これにより、モデルの学習効率や精度、文脈理解を高め、アウトプットの品質を向上させることができます。
・和文に対するタグの正確性
タグ付けについては、1人目の作業者が判断した内容について、品質管理担当者がダブルチェックを行うようにしています。その上でチェックツールを使用してケアレスミスや見落としがないよう再確認します。
用途や文脈によってはどういったタグを付けるべきか判断が難しい内容もあります。そのため、不明点が出た時点で判断基準や対応方法のすり合わせをお客様と行います。確認した内容はマニュアルに落とし込み、案件の都度ルールを見直しつつ更新点を作業者と共有することを徹底しています。マニュアル化することで、作業を属人化させず、同じ判断基準をもって一貫性を保つよう取り組んでいます。
また、納品前には、全行程を把握している品質管理担当者が和文、英文、タグを含め全体の最終チェックを行うことで、判断のブレを最小限にしています。
3-3. 高品質の訳文
LLM開発にはベースとなるデータセットの精度が極めて重要で、正確で自然な文同士のバイリンガルデータが学習素材として必要となります。このデータに誤訳、機械的な訳、直訳的なデータが含まれると、モデルはそのデータが正しいと学習し、結果的に生成されるアウトプットの信頼性低下につながります。用途や分野によっては、生成されるアウトプットの誤りがリスクになることもあります。
また、誤訳やバイリンガルデータの非対応といったノイズが少なく正確なデータであれば、モデルも効率よく学習することができ、誤学習の防止や学習効率の向上が見込めます。
・英語<=>日本語の翻訳
ヒューマンサイエンスは約30年の翻訳実績があり、英語<=>日本語の言語だけでも約500名の翻訳者・レビューアが登録されています。IT、医療、金融、特許、日常会話といった様々な分野のデータセットが必要なプロジェクトでは、分野ごとに適した翻訳者・レビューアをアサインしています。
翻訳とレビュー後は、自社開発のQAツールを組み合わせて文法エラーやタイポ、数値チェックを実施します。人手翻訳と技術を組み合わせることで、より自然で正確性の高い訳文となるようブラッシュアップすることができます。
4. まとめ:LLM開発における作業の依頼はヒューマンサイエンスへ
4-1. 教師データ作成数4,800万件の豊富な実績
ヒューマンサイエンスでは自然言語処理に始まり、医療支援、自動車、IT、製造や建築など多岐にわたる業界のAIモデル開発プロジェクトに参画しています。これまでGAFAMをはじめとする多くの企業様との直接のお取引により、総数4,800万件以上の高品質な教師データをご提供してきました。数名規模のプロジェクトからアノテーター150名体制の長期大型案件まで、業種を問わず様々な教師データ作成やデータラベリング、データの構造化に対応しています。
4-2. クラウドソーシングを利用しないリソース管理
ヒューマンサイエンスではクラウドソーシングは利用せず、当社が直接契約した作業担当者でプロジェクトを進行します。各メンバーの実務経験や、これまでの参加プロジェクトでの評価をしっかりと把握した上で、最大限のパフォーマンスを発揮できるチームを編成しています。
4-3. キュレーション・アノテーションのみならず生成系AI LLMデータセット作成・構造化にも対応
データ整理ためのラベリングや識別系AIのアノテーションのみでなく、生成系AI・LLM RAG構築のためのドキュメントデータの構造化にも対応します。創業当初から主な事業・サービスとしてマニュアル制作を行い、様々なドキュメントの構造を熟知している当社ならではのノウハウを活かした最適なソリューションを提供いたします。
4-4. 自社内にセキュリティルームを完備
ヒューマンサイエンスでは、新宿オフィス内にISMSの基準をクリアしたセキュリティルームを完備しています。そのため、守秘性の高いデータを扱うプロジェクトであってもセキュリティを担保することが可能です。当社ではどのプロジェクトでも機密性の確保は非常に重要と捉えています。リモートのプロジェクトであっても、ハード面の対策のみならず、作業担当者にはセキュリティ教育を継続して実施するなど、当社の情報セキュリティ管理体制はお客様より高いご評価をいただいております。