"I don't know which translation engine is good."
This is a common concern we hear from customers considering the introduction of machine translation.
While automatic evaluations such as BLEU scores and TER scores are well-known methods for assessing the quality of machine translation, these evaluations are mechanical and often do not align with actual quality.
Therefore, at Human Science, we not only conduct automatic evaluations by machines but also assessments by native translators to accurately determine the quality of machine translation engines.
Evaluation Method
We evaluate the output of 3 to 5 engines using two methods: human evaluation (by native translators) and automatic evaluation (BLEU score, TER score).
Quality assessment by multiple native translators
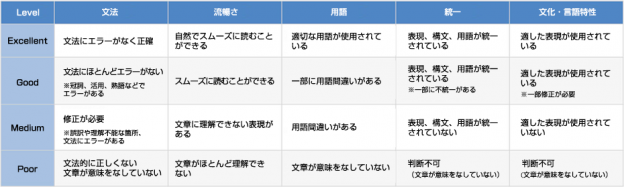
The output of the MT engine will be evaluated from five perspectives: "Grammar", "Fluency", "Terminology", "Consistency", and "Cultural and Linguistic Characteristics" using four criteria: "Excellent", "Good", "Medium", and "Poor".
- Excellent… very good quality. It is comparable to human translation and requires almost no corrections.
- Good… Good quality. There are a few errors, but the meaning of the original text can be understood.
- Medium…Fair quality. Needs improvement.
- Poor… Poor quality. It needs to be translated from scratch.
After machine translation, a process called post-editing is necessary to improve the translated text. The quality of the output is evaluated based on the following two criteria.
- Quality that can be improved through post-editing
- Is it better quality to translate from scratch rather than post-editing?
Depending on the target quality in post-editing, the quality that can be achieved through post-editing may differ from the quality that is better to translate from scratch. Therefore, we will conduct an evaluation after hearing your target quality.
Automatic Evaluation by Score
- BLEU Score
- TER Score
It is the most widely used automatic evaluation metric in the evaluation of MT systems.
The translation accuracy is assessed by comparing the reference translation (correct answer) with the translation result based on similarity. A score is calculated between 0% and 100%, and the higher the score, the better the quality. A score of 50% or higher indicates good quality.

This is an automatic evaluation metric for calculating the error rate of translations.
It calculates the ratio of modifications (replacements, insertions, deletions, shifts) made to the translation results in order to obtain a reference translation (correct answer).
The error rate is calculated on a scale from 0% to 100%, where a lower score indicates fewer errors and a reduced burden of post-editing.
If the value is below 30%, it can be considered to have good quality.

Quality Evaluation Analysis Report
This is a sample of a report that was submitted as a deliverable in an actual project, which compares the quality of three machine translation engines.

Related Services
Machine Translation Evaluation Services
Scheduled Machine Translation Seminar
We hold machine translation seminars every month.
If you would like to receive seminar announcement emails, please register using the button below.