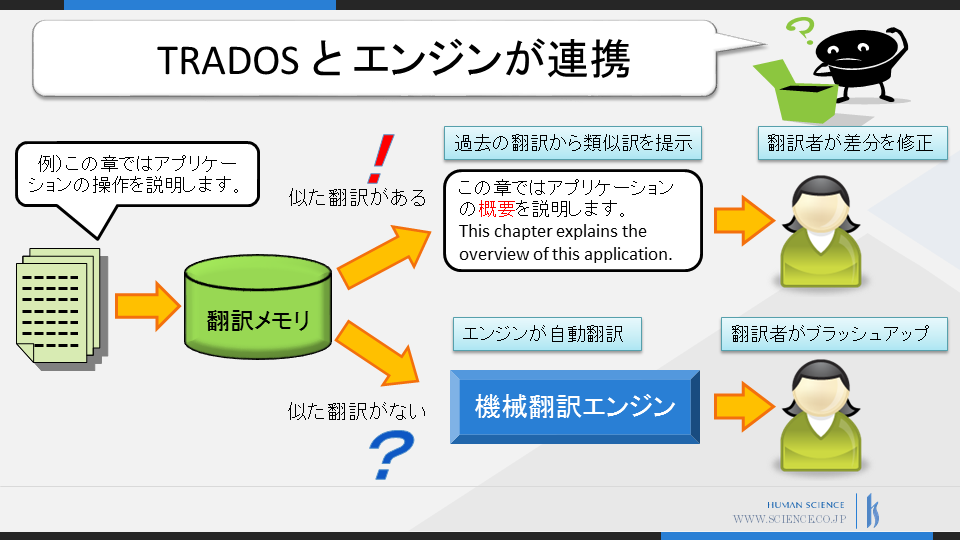
One of the common questions asked when introducing machine translation is,
"Can we utilize our existing translation assets?"
It seems that many of you have a desire to leverage the database of source and translated texts that you have accumulated in formats such as translation memories,
for machine translation as well.
This time, we will introduce the "combination of machine translation engines and translation support tools" that can further improve efficiency while making better use of translation assets.
●Is a similar translation in the corpus a correct translation?
When it comes to leveraging past assets in machine translation,
the first thing that comes to mind is, of course, the "corpus."
By feeding a bilingual corpus that links previously translated source texts and their translations into a statistical-based engine,
we can improve the accuracy of translations.
However, there are drawbacks to how this asset can be utilized.
This is the difficult part of the statistical-based engine,
which is that just because there are similar translations in the corpus, it does not necessarily mean that it will result in a good translation.
Let me explain using the example of English to Japanese translation.
Let's assume the following translation was included in the corpus.
——————————————————————
Press the [Finish] button to close the window.
Press the [Finish] button to close the window.
——————————————————————
In that case, I have a feeling that a relatively "good translation" will be output for the following original text.
——————————————————————
Press the [OK] button to close the window.
——————————————————————
However, in reality, translations like this can be output.
——————————————————————
Press the [OK] button to close the window
——————————————————————
*This is merely a simplified model example and does not represent the output results of a specific engine or the quality of translation.
There are various factors to consider, such as the engine's analysis not going as intended,
being influenced by other translations in the corpus, and so on.
Some may think, "If it's going to turn out like this, wouldn't it be faster to refer to past translations and translate it myself rather than post-editing this?"
There may be those who feel this way.
In fact, that's exactly right!
●If there are similar translations, use translation support tools for translation
Translation support tools such as TRADOS provide a numerical representation of the "match rate" when there are similar translations in past translation assets (= translation memory).
In the above example, if there is "Press the [Finish] button to close the window." in the translation memory,
when trying to translate "Press the [OK] button to close the window.",
it will suggest something like "There is a translation that matches 90%.".
Therefore, when there is a high match in the translation memory, we refer to that for translation,
and only when there is none do we perform machine translation + post-editing to
improve accuracy while efficiently progressing with the translation.
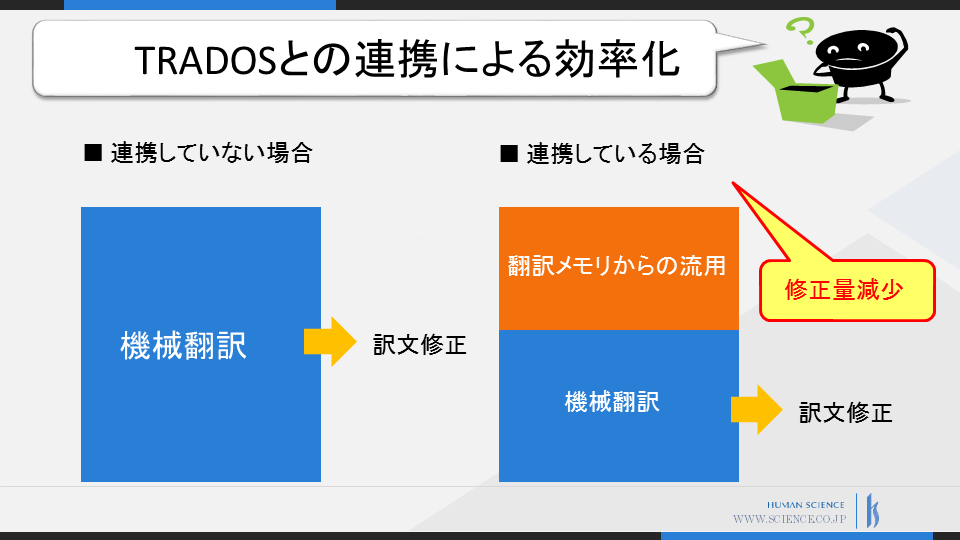
In the cases we have handled,
machine translation is applied only to those with a certain match rate threshold that is lower,
while those with a higher match rate are translated by hand with reference to translation memory,
resulting in a reduction of translation costs by about 15%.
"So, what should the threshold for the match rate be?" This is a point that
some of you may be concerned about.
However, this value varies depending on the quality and quantity of the target documents, engines, translation memories, and corpora.
Therefore, by conducting sample translations at several thresholds in advance,
you can determine the appropriate threshold and operate more reliably.
In addition, regarding the integration of translation support tools and machine translation engines,
there are some that can be integrated as standard features,
and others that can be integrated through APIs.
For those who want to implement machine translation but also want to leverage past assets,
the ability to integrate with translation support tools will be an important point when selecting a translation engine.
●Summary
This time, we introduced how to effectively combine machine translation engines and translation support tools to improve accuracy while enhancing efficiency.
"I want to use this engine, but is integration with translation support tools possible?"
"For our translation assets and target documents, what percentage threshold is appropriate?" If you have any concerns, please feel free to consult with Human Science.
Related Services
Trados/Memsource Machine Translation Integration Solution