 Text Annotation
Text Annotation Audio Annotation
Audio Annotation Image & Video Annotation
Image & Video Annotation Generative AI, LLM, RAG Data Structuring
Generative AI, LLM, RAG Data Structuring
 AI Model Development
AI Model Development In-House Support
In-House Support For the medical industry
For the medical industry For the automotive industry
For the automotive industry For the IT industry
For the IT industry For the manufacturing industry
For the manufacturing industry

- Table of Contents
-
- 1. Introduction
- 2. Project Example: Creating a Japanese-English Dataset for LLM Development
- 3. Three Key Points in Creating Datasets for LLM Development
- 3-1. Creating Diverse and Large-scale Datasets
- 3-2. Accuracy of Tags
- 3-3. High-Quality Translations
- 4. Summary: Requesting Tasks for LLM Development to Human Science
- 4-1. A rich track record of creating 48 million pieces of training data
- 4-2. Resource Management Without Using Crowdsourcing
- 4-3. Support for not just curation and annotation, but also the creation and structuring of generative AI LLM datasets
- 4-4. Fully equipped security room within the company
1. Introduction
In recent years, the application areas of large language models (LLM: Large Language Model), including ChatGPT, have expanded dramatically. One of the factors supporting their accuracy can be said to be diverse and large volumes of high-quality language datasets.
Against this backdrop, Human Science supports the creation of bilingual datasets for LLM development. This article introduces how to create datasets, the challenges you may face, and countermeasures. We hope it will be a helpful reference for those who have questions about creating bilingual data for LLM development.
2. Project Example: Creating a Japanese-English Dataset for LLM Development
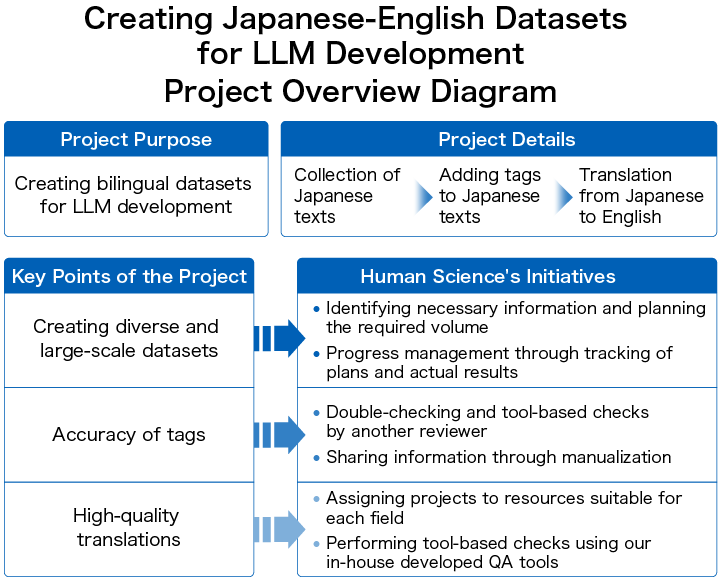
The purpose of the project is to create a dataset for the LLM that the client is developing in-house. Such a dataset consists of Japanese sentences, English sentences with the same content corresponding to the Japanese sentences, and tags (information tagged based on the content included in the Japanese sentences). Each sentence is treated as a single unit, and a large number of data entries are created.
In creating this dataset, the main tasks are as follows.
・Collection of Japanese Texts
First, we collect or create Japanese texts. The target Japanese texts cover a wide range of fields such as IT, medical, finance, patents, and everyday conversation.
・Adding Tags to Japanese Sentences
Tags are added to explain what kind of information is contained in the target Japanese sentences.
For example, consider the following sentence.
“Kabushiki Human Science Co., Ltd. was established in 1985, and its headquarters are located in Tokyo.”
This sentence contains information such as “Organization Name” (Kabushiki Human Science Co., Ltd.), “Date” (1985), and “Place Name” (Tokyo), so tags like “Organization Name,” “Date,” and “Place Name” are attached. The required information may vary depending on the project, but tags are assigned in this manner.
・Translation from Japanese to English
Human translation is performed from Japanese to English to create bilingual data consisting of Japanese and English sentences.


3. Three Key Points in Creating Datasets for LLM Development
Next, we will introduce the important points in creating datasets for LLM development and how to address those points.
3-1. Creating Diverse and Large-scale Datasets
In LLM development, a large dataset is required to train the model. Language is extremely diverse, encompassing a wide range of features such as vocabulary and expressions, spoken and written language, styles, and the use of honorifics. Therefore, a small dataset cannot cover this diversity, which may result in a loss of generalizability.
Additionally, with a small amount of data, there tends to be bias toward specific speakers, styles, or content. By using a large dataset, this bias can be relatively mitigated, resulting in a more neutral model.
・Creation of Japanese Text Datasets
First, regarding the collection of Japanese text, if done without a plan, it may become biased toward certain fields or media. Therefore, it is important to initially decide the required number for each category such as field, media, situation, speaker, and necessary information, and to plan accordingly. By continuously comparing the plan with actual results and tracking them, if there are any discrepancies in the number collected compared to the plan, adjustments can be made as needed to proceed with data collection and creation in a well-balanced manner.
In addition, Human Science has many annotators registered who have passed rigorous trials, not limited to translators and reviewers. Furthermore, by collaborating with our in-house development team, it is also possible to develop project-specific auxiliary tools. Therefore, even tasks that would require significant human and time costs in the customer's environment can be handled with a system that ensures quality and technical reliability.
3-2. Accuracy of Tags
Tagging performed during dataset creation for LLM development requires accuracy. For example, consider the following sentence.
"Salary for January"
The term "January" in this sentence can have two meanings depending on its reading. If read as "ichigatsu," it refers to January, the first month on the calendar, representing a unit of date. However, if read as "hitotsuki," it functions as a counter indicating a quantity or duration of one month.
Language is thus polysemous depending on context, but by attaching information as tags, the sentence structure and context can be explicitly indicated. This enhances the model’s learning efficiency, accuracy, and contextual understanding, thereby improving the quality of the output.
・Accuracy of Tagging for Japanese Text
Regarding tagging, the content judged by the first worker is double-checked by the quality control personnel. Additionally, a checking tool is used to reconfirm and prevent careless mistakes or oversights.
Depending on the purpose and context, it can be difficult to determine which tags should be applied. Therefore, whenever uncertainties arise, we coordinate with the client to align on the criteria and response methods. The confirmed details are documented in a manual, and we thoroughly ensure that rules are reviewed and updates are shared with the workers for each project. By creating a manual, we avoid making the work dependent on individual skills and strive to maintain consistency by applying the same judgment criteria.
Also, before delivery, a quality control manager who oversees the entire process conducts a final comprehensive check of the Japanese text, English text, and tags to minimize inconsistencies in judgment.
3-3. High-Quality Translations
The accuracy of the base dataset is extremely important for LLM development, and bilingual data consisting of accurate and natural sentences is required as training material. If this data contains mistranslations, mechanical translations, or literal translations, the model will learn that this data is correct, which will ultimately lead to a decrease in the reliability of the generated output. Depending on the use case and field, errors in the generated output can also pose risks.
Furthermore, if the data is accurate with minimal noise such as mistranslations or unsupported bilingual data, the model can learn efficiently, which helps prevent incorrect learning and improves learning efficiency.
・English<=>Japanese Translation
Human Science has about 30 years of translation experience, with approximately 500 translators and reviewers registered for the English<=>Japanese language pair alone. For projects requiring datasets in various fields such as IT, medical, finance, patents, and everyday conversation, we assign translators and reviewers suitable for each field.
After translation and review, we combine our in-house developed QA tools to check for grammatical errors, typos, and numerical accuracy. By combining human translation with technology, we can polish the translations to be more natural and highly accurate.
4. Summary: Requesting Tasks for LLM Development to Human Science
4-1. Extensive track record of creating 48 million teacher data entries
At Human Science, we are involved in AI model development projects across various industries, starting with natural language processing, including medical support, automotive, IT, manufacturing, and construction. Through direct transactions with many companies, including GAFAM, we have provided over 48 million high-quality training data. We handle a wide range of training data creation, data labeling, and data structuring, from small-scale projects to long-term large projects with a team of 150 annotators, regardless of the industry.
4-2. Resource Management Without Using Crowdsourcing
At Human Science, we do not use crowdsourcing. Instead, projects are handled by personnel who are contracted with us directly. Based on a solid understanding of each member's practical experience and their evaluations from previous projects, we form teams that can deliver maximum performance.
4-3. Support for Not Only Curation and Annotation but Also Generative AI LLM Dataset Creation and Structuring
In addition to labeling for data organization and annotation for identification-based AI systems, Human Science also supports the structuring of document data for generative AI and LLM RAG construction. Since our founding, our primary business has been in manual production, and we can leverage our deep knowledge of various document structures to provide you with optimal solutions.
4-4. Fully equipped security room within the company
Within our Shinjuku office at Human Science, we have secure rooms that meet ISMS standards. Therefore, we can guarantee security, even for projects that include highly confidential data. We consider the preservation of confidentiality to be extremely important for all projects. When working remotely as well, our information security management system has received high praise from clients, because not only do we implement hardware measures, we continuously provide security training to our personnel.

































































































