 Text Annotation
Text Annotation Audio Annotation
Audio Annotation Image & Video Annotation
Image & Video Annotation Generative AI, LLM, RAG Data Structuring
Generative AI, LLM, RAG Data Structuring
 AI Model Development
AI Model Development In-House Support
In-House Support For the medical industry
For the medical industry For the automotive industry
For the automotive industry For the IT industry
For the IT industry For the manufacturing industry
For the manufacturing industry

Recently, many companies have started adopting generative AI and LLMs, but it is not uncommon to face challenges such as "unstable translation quality" and "how to ensure the accuracy of training data."
At Human Science, we are also responding to customer requests to "improve LLM translation accuracy" by carefully evaluating the quality of English-Japanese bilingual data manually. This article introduces the flow and results of that project.

- Table of Contents
-
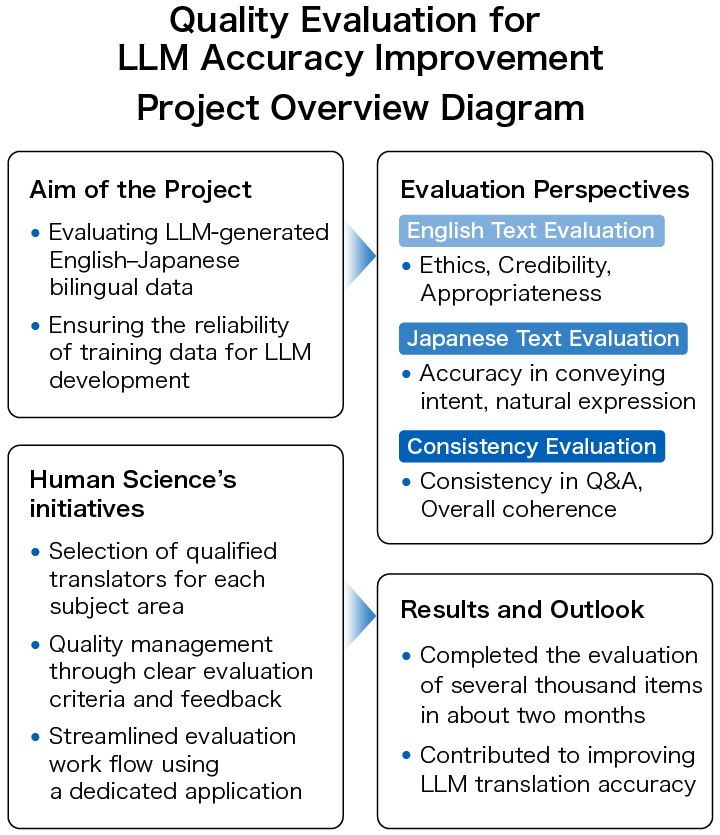
- 1. Project Overview: Bilingual Data Evaluation for Improving LLM Translation Accuracy
- 1-1. How to Evaluate English-Japanese Bilingual Data?
- 2. Mechanisms to Enhance Evaluation Accuracy—Human Science’s Innovations
- 3. Results and Future Prospects—Contributing to LLM Accuracy Improvement
- 4. Summary: Requesting Tasks for LLM Development to Human Science
1. Project Overview: Bilingual Data Evaluation for Improving LLM Translation Accuracy
You will provide a dataset consisting of English texts collected by the client from various fields (such as medical, scientific, financial, political, sports, economic, cultural, etc.) along with their corresponding Japanese texts (Japanese translations generated by the LLM). Human Science conducts "data evaluation" on the bilingual English-Japanese data to determine whether it meets a certain quality level.
1-1. How to Evaluate English-Japanese Bilingual Data?
The evaluation targets are bilingual data consisting of mechanically collected English texts and Japanese translations generated by the LLM. How should the accuracy of this bilingual data be evaluated? We will introduce the perspectives for evaluation.
・English Text Evaluation – How to Judge Data Eligibility?
In the evaluation, we first check whether the English text is suitable as training data. For example, from the perspective of ethical appropriateness, if the content includes discriminatory material or falsehoods and misinformation that contradict facts, the English text is deemed ineligible and evaluated as "not meeting the passing criteria".
・Japanese Text Evaluation – How to Judge Accuracy and Naturalness?
Next, we evaluate whether the quality of the Japanese text meets the passing criteria by comparing it against the English text based on several evaluation items. The evaluation criteria include whether the intent of the English text is conveyed and whether the Japanese expression is natural, among other points. Even if the Japanese expression is natural and easy to read, the evaluation will be lowered if the intent of the English text is not properly captured or if the expression causes misunderstandings.
・Consistency Evaluation – What Are the Unique Challenges of LLMs?
The bilingual data consists of the main text and related questions and answers. In addition to the accuracy and readability of the Japanese text, the evaluation also covers the consistency of the text, such as whether the content of the questions and answers aligns with the main text and whether the questions and answers themselves are coherent. A characteristic of LLMs is that they do not simply produce a literal Japanese translation but may summarize, paraphrase, or add additional information. Therefore, it is necessary not only to check for word substitutions but also to thoroughly understand and evaluate whether the intended meaning of the English text is accurately conveyed.


2. Mechanisms to Enhance Evaluation Accuracy—Human Science’s Innovations
・Selection of Optimal Evaluators by Field
Since the evaluation targets spanned a wide range of fields, from specialized content such as medical, scientific, and financial topics to general news articles, Human Science selects the most suitable members from among translators for each field.
Evaluating bilingual data requires judgment skills based on consistent standards of translation quality, not merely checking whether the English has been replaced by Japanese, but whether the intent of the English text is correctly conveyed and whether the Japanese readability meets a certain level. Human Science’s translators, who have accumulated extensive experience in practical translation over many years, leverage their expertise to conduct highly accurate evaluations.
・Evaluation Criteria and Feedback System to Maintain Quality
To keep the evaluation criteria consistent, we closely coordinate with our clients to confirm the quality level and share this with the workers.
When the evaluation work actually begins, irregular cases that were not anticipated by the client at the request stage may arise. Especially with bilingual data generated by LLMs, there are occasional issues that do not occur in Japanese texts translated by humans. For example, other languages or garbled characters may be mixed into the Japanese text, or although not mistranslations, inconsistencies in terminology throughout the text may impair the intended meaning. For these cases, it is necessary to clearly define where to set the scoring criteria. We work together with the client on this point, clarifying the standards for even minor details through email and meetings.
Additionally, we provide frequent feedback to workers until they can perform evaluations according to a consistent standard. By assigning a final checker to review the data before submission, even when multiple resources are deployed to proceed intensively with the work, we can suppress variations in evaluation criteria and stabilize quality.
・Boost Efficiency with a Dedicated App! Support from the Technical Team
In one project, the client requested input data in CSV format and output data delivered by Human Science in JSON format. The workflow involves adding multiple evaluation items, their scores, and comments if necessary to the bilingual data input in CSV format, then outputting it in JSON format.
If the client does not have a dedicated evaluation platform, Human Science’s technical team develops a specialized "evaluation app." English and Japanese texts are displayed side by side on the screen, allowing evaluators to complete score input for evaluation items on the same screen. Based on feedback from evaluators, the app has been updated several times through trial and error to achieve an intuitive and easy-to-understand UI that facilitates evaluation. Using the dedicated app helps streamline the evaluation process and prevents input errors and omissions.
Even clients without a platform can benefit from Human Science’s flexible tool development and operational support. Please feel free to contact us first.


3. Results and Future Prospects—Contributing to LLM Accuracy Improvement
In projects with several thousand bilingual data entries, evaluations were completed in about two months. Within limited time and budget, the evaluation work was smoothly completed, providing valuable data for improving the accuracy of LLMs. Going forward, we will continue to handle larger-scale evaluation projects with expertise tailored to each field and flexible technical support.
4. Summary: Requesting Tasks for LLM Development to Human Science
Over 48 million pieces of training data created
At Human Science, we are involved in AI model development projects across various industries, starting with natural language processing, including medical support, automotive, IT, manufacturing, and construction. Through direct transactions with many companies, including GAFAM, we have provided over 48 million high-quality training data. We handle a wide range of training data creation, data labeling, and data structuring, from small-scale projects to long-term large projects with a team of 150 annotators, regardless of the industry.
Resource management without crowdsourcing
At Human Science, we do not use crowdsourcing. Instead, projects are handled by personnel who are contracted with us directly. Based on a solid understanding of each member's practical experience and their evaluations from previous projects, we form teams that can deliver maximum performance.
Supports not only curation and annotation but also the creation and structuring of generative AI LLM datasets
In addition to labeling for data organization and annotation for identification-based AI systems, Human Science also supports the structuring of document data for generative AI and LLM RAG construction. Since our founding, our primary business has been in manual production, and we can leverage our deep knowledge of various document structures to provide you with optimal solutions.
Secure room available on-site
Within our Shinjuku office at Human Science, we have secure rooms that meet ISMS standards. Therefore, we can guarantee security, even for projects that include highly confidential data. We consider the preservation of confidentiality to be extremely important for all projects. When working remotely as well, our information security management system has received high praise from clients, because not only do we implement hardware measures, we continuously provide security training to our personnel.

































































































