テキストアノテーション
テキストアノテーション 音声アノテーション
音声アノテーション 画像・動画アノテーション
画像・動画アノテーション 生成AI、LLM、RAGデータ構造化
生成AI、LLM、RAGデータ構造化
 AIモデル開発
AIモデル開発 内製化支援
内製化支援 医療業界向け
医療業界向け 自動車業界向け
自動車業界向け IT業界向け
IT業界向け 製造業向け
製造業向け

ChatGPTの登場により、これまで「識別系」だったAIのトレンドはLLMに代表される「生成系」へと大きく舵を切っています。今回はLLMについて解説するとともに、LLMだけでは難しいとされている、社内データを活用するための技術、RAGについて解説いたします。
1. LLMとは
LLM(Large Language Models、大規模言語モデル)とは、膨大なテキストデータをディープラーニング技術によって学習することにより構築されたAIモデルです。LLMは従来の言語モデルと比較して「計算量」「データ量」「パラメータ数」の三要素を大幅に強化しています。たとえばパラメータ量では従来のモデルが数百万から数十億であったのに対して、LLMでは数百億から数兆という想像を絶する量を持っています。高性能のGPUによってこれらの要素を高速処理できるようになり、幅広い分野にわたって高度な言語理解とテキスト生成が可能となりました。
こうしたLLMの代表的な例がChatGPTです。ユーザーが、話し言葉(自然言語)で質問やプロンプトを入力するだけで、会話しているように回答したり、プログラミングコードを生成したりするモデルとして、登場直後からさまざまな業界で大きな注目を集めています。
ChatGPTの他にも、Google LaMDAやGEMINIといったさまざまなLLMが発表され進化し続ける中で、ビジネスにおいてもその活用の可能性は多岐にわたって高まっています。
2. LLMの課題
とはいえ、LLMにも課題があります。それは「ハルシネーション」と呼ばれるものです。これは、LLMによって生成されたテキストが事実や現実に基づかない誤った情報や、完全に架空の内容を含む現象を指します。LLMモデルはテキストや単語の出現確率に基づいて単語を出力します。情報が正確かどうかということを考慮してテキストを生成しているわけではありません。学習していないことについてもテキストを生成してしまいます。
「ハルシネーション」が起こる原因として、LLMが最新の情報を学習していない、クローズドデータ(社内データなど、外部ネットワークから遮断されたデータ)にアクセスできない、といったことがあげられます。
こうした課題に対して、精度を高めるためにLLMを特定の分野について強化するファインチューニングや追加学習という技術があります。この技術は、精度を上げることが可能である一方で、膨大なデータ量と計算資源が必要であるというデメリットもあります。こうしたデメリットを解消するために注目を集めている技術がRAGです。
3. RAGとは
RAG(Retrieval-Augmented Generation検索拡張生成)はLLMに検索技術を組み合わせたものです。ファインチューニングや追加学習がLLMそのものを学習させ精度向上を図るのに対し、RAGはデータ検索と抽出を行い、その内容をもとにLLMに高精度の回答を出力させることができます。
RAGは単にLLMに検索機能を追加するだけではなく、データ整備や検索基盤の構築など、いくつかの工程を経て実装されます。一般的なRAG導入の流れは次の通りです。
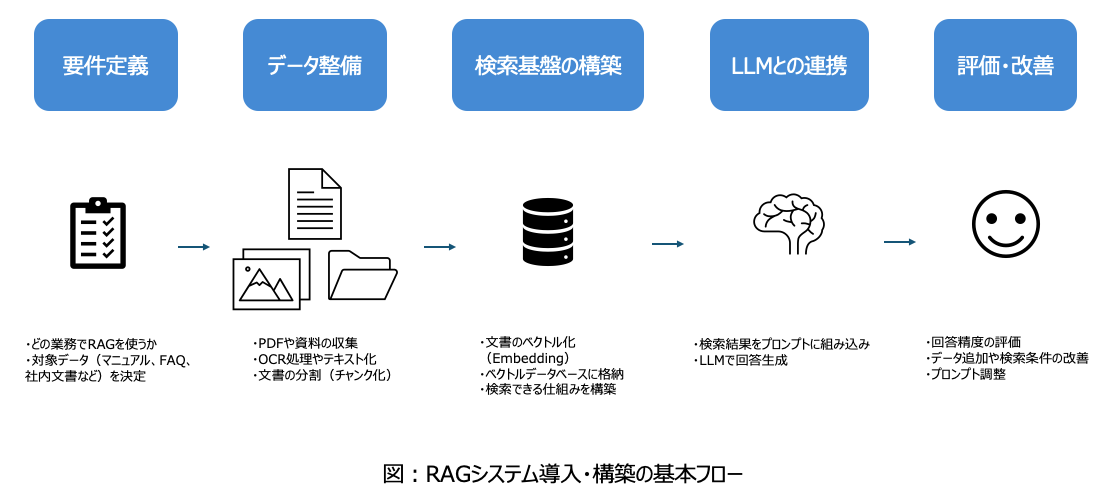
このようにRAGの導入では、単にLLMを利用するだけでなく、検索対象となるデータの整備や検索基盤の設計が重要になります。特に社内文書やマニュアルなどの非構造データを整備する工程は、精度を左右する重要なポイントとなります。
ここで、各社から提供されたサービスを特にカスタマイズや追加学習せず、プレーンな状態のLLM(ベースLLM)としてそのまま使用する場合と、RAGを用いて自社に特化した情報を扱えるようにした場合(LLM+RAG)の特徴をまとめて比較してみましょう。
| 観点 | ベースLLM | LLM+RAG |
|---|---|---|
| 学習の範囲 | 学習済みのデータに依存しており、モデル構築時点までの情報しか持たない。そのため、最新ニュースや社内独自の情報には対応できない。 | 外部データベースや検索エンジンから必要な情報を随時取得できるため、最新情報や企業内のナレッジなど特定領域の知識を反映できる。 |
| 正確性 | 出力は確率的な推測に基づくためハルシネーションが発生することがある。 | 回答の根拠となる文書を検索・参照するため、情報の裏付けが明確で、正確性の高い応答が期待できる。 |
| 運用のしやすさ | 知識を更新するには追加学習や再学習が必要で、膨大なコストや時間がかかる。運用段階での柔軟な知識更新は難しい。 | データベースや検索対象の文書を更新すれば即座に回答に反映される。運用コストが低く、知識更新のスピードも速い。 |
| 導入の容易さ | APIを通じてすぐに利用できるため、PoC(実証実験)や小規模導入に比較的容易。ただし社内データ活用には追加の工夫が必要。 | 検索基盤(ベクトルデータベースや検索システム)の構築が必要で導入ハードルは高めだが、一度整備すればスケーラブルな運用が可能。 |
| ユースケース | 一般的な知識Q&A、文章要約、アイデア出し、プログラミング補助など「汎用的・創造的なタスク」に強みがある。 | FAQ自動応答、社内ドキュメント検索など「社内特化・独自情報が必要なタスク」に強みがある。 |
RAGはファインチューニングや追加学習に比べ低コストで運用が可能であるのに加え、LLMでは難しかった最新情報やクローズドデータへのアクセスが可能になります。このように、LLMの言語理解能力とRAGによる社内情報など特定の領域のデータ検索能力を組み合わせることによって、さまざまな業務の効率化が実現できます。その範囲は多岐にわたります。下記はそうした効率化の例です。
ナレッジマネジメント
ナレッジマネジメントでは、組織内の知識を効果的に収集、整理、共有することが重要です。RAGによって、大量の文書やデータベースから関連情報を迅速に検索し、必要なナレッジを抽出することが可能です。これにより、必要な情報に素早くアクセスできるため、業務効率が大幅に向上します。 例えば、製造業であれば、設計標準、加工工程図や業務フローチャート、品質管理基準書など、膨大な文書が蓄積されているでしょう。RAGを活用できればこれらの文書の中から必要な情報を素早く検索することが可能となります。
コンテンツ生成
ウェブサイトやブログでその企業独自の事例や強みを発信するためのコンテンツ生成が可能となります。RAGによって関連情報を引き出すことによって、より正確な情報発信が短時間で効率よく行えます。 例えば、過去の成功事例などを対外発信したい場合に、RAGを活用して、その事例についての様々な技術レポートや担当者の報告書などの多角的な情報を効率的に収集・統合できれば、自社の強みをより訴求するコンテンツ生成が可能となります。
カスタマーサポート
マニュアルが数百ページに及ぶ製品を複数リリースしているメーカーであれば、顧客からの問い合わせに対し迅速かつ的確なサポートを行うことは最重要の業務の一つです。該当する製品マニュアルを検索して正確な回答をするのに時間がかかってしまっては、顧客満足度という面で大きな損失となってしまいます。 RAGを活用すれば、過去の問い合わせデータを分析し、最適な回答を生成することが可能となり、顧客満足度の向上が期待できます。またサポートチームの負担を大幅に削減することが可能となり業務効率化も実現できます。
4. RAGの課題
RAGは社内データなど限られたデータの中を検索して結果を出力することができます。裏を返せば、このデータが間違っていたら不正解の回答を出力してしまいますし、データが存在しない場合は回答を出力することができません。また、スキャンされた設計図、PDF、パワーポイント資料など構造化されていないデータについてはRAGが検索しやすいように整備する必要があります。例えば、PDFであれば、OCR処理を施す、PDF化する前のパラグラフなど文書レイアウト構造が認識できるwordファイルを利用する(もしくは、word版を作成する)、といった方法があります。
そのため、RAGを導入する際には、データのメンテナンスやクレンジングといった整備が必要となります。また、機密情報を取り扱う場合には、アクセス権の制限などセキュリティ対策も必須となります。
5. まとめ
LLMとRAGを活用することで、さまざまな業務において効率化と生産性の向上が期待できます。また、新たな価値創出をサポートするために活用することも可能です。とはいえ、それぞれの技術には正確性などの面で課題があります。これらの課題に対してLLMのファインチューニングや追加学習もしくはRAGの精度向上のためのデータ整備が必要です。とはいえ、社内に散らばっている大量のドキュメントを構造化・整備する作業には多大な工数がかかります。そのために社内のリソースを割くことが難しい場合には、外部ベンダーに依頼することも一つの方法です。
6. ヒューマンサイエンスのアノテーション、LLM RAGデータ構造化代行サービス
教師データ作成数4,800万件の豊富な実績
ヒューマンサイエンスでは自然言語処理に始まり、医療支援、自動車、IT、製造や建築など多岐にわたる業界のAIモデル開発プロジェクトに参画しています。これまでGAFAMをはじめとする多くの企業様との直接のお取引により、総数4,800万件以上の高品質な教師データをご提供してきました。数名規模のプロジェクトからアノテーター150名体制の長期大型案件まで、業種を問わず様々なアノテーションやデータラベリング、データの構造化に対応しています。
クラウドソーシングを利用しないリソース管理
ヒューマンサイエンスではクラウドソーシングは利用せず、当社が直接契約した作業担当者でプロジェクトを進行します。各メンバーの実務経験や、これまでの参加プロジェクトでの評価をしっかりと把握した上で、最大限のパフォーマンスを発揮できるチームを編成しています。
アノテーションのみならず生成系AI LLMデータセット作成・構造化にも対応
データ整理ためのラベリングや識別系AIのアノテーションのみでなく、生成系AI・LLM RAG構築のためのドキュメントデータの構造化にも対応します。創業当初から主な事業・サービスとしてマニュアル制作を行い、様々なドキュメントの構造を熟知している当社ならではのノウハウを活かした最適なソリューションを提供いたします。
自社内にセキュリティルームを完備
ヒューマンサイエンスでは、新宿オフィス内にISMSの基準をクリアしたセキュリティルームを完備しています。そのため、守秘性の高いデータを扱うプロジェクトであってもセキュリティを担保することが可能です。当社ではどのプロジェクトでも機密性の確保は非常に重要と捉えています。リモートのプロジェクトであっても、ハード面の対策のみならず、作業担当者にはセキュリティ教育を継続して実施するなど、当社の情報セキュリティ管理体制はお客様より高いご評価をいただいております。
内製支援
弊社ではお客様の作業や状況にマッチしたアノテーション経験人材やプロジェクトマネージャーの人材派遣にも対応しています。お客様常駐下でチームを編成することも可能です。またお客様の作業者やプロジェクトマネージャーの人材育成支援や、お客様の状況に応じたツールの選定、自動化や作業方法など、品質・生産性を向上させる最適なプロセスの構築など、アノテーションやデータラベリングに関するお客様のお困りごとを支援いたします。