 Text Annotation
Text Annotation Audio Annotation
Audio Annotation Image & Video Annotation
Image & Video Annotation Generative AI, LLM, RAG Data Structuring
Generative AI, LLM, RAG Data Structuring
 AI Model Development
AI Model Development In-House Support
In-House Support For the medical industry
For the medical industry For the automotive industry
For the automotive industry For the IT industry
For the IT industry For the manufacturing industry
For the manufacturing industry

Machine learning is necessary to improve the accuracy of AI. The data used for this is called training data. Here, we will discuss what effective training data for machine learning looks like.
- Table of Contents
-
- 1. What is teacher data?
- 1-1. What is the relationship between AI, machine learning, training data, and annotation?
- 1-2. Essential Training Data for AI Learning
- 1-3. Time-Consuming Annotation
- 1-4. How much quantity is needed?
- 1-5. What is the difference between teacher data and training data?
- 1-6. Three Approaches to Machine Learning
- 2. Why is the quality of training data considered important?
- 2-1. What is High-Quality Training Data
- 2-2. Why is the quality of training data considered important?
- 3. Procedure for Creating Training Data
- 3-1. Clarification of Purpose
- 3-2. Definition of Required Annotation Requirements
- 3-3. Data Collection
- 3-4. Implementation of Annotations
- 4. Three Key Points in Producing Training Data
- 4-1. Standardization of Work Rules
- 4-2. Management System Suitable for Annotation
- 4-3. Ensuring Security Levels
- 5. Human Science Teacher Data Creation and LLM RAG Data Structuring Outsourcing Service
1. What is teacher data?

1-1. What is the relationship between AI, machine learning, training data, and annotation?
First, let's organize how AI (artificial intelligence) works. The structure by which AI learns is the same as that of humans. AI also improves its judgment ability and processing speed through repeated training. This training is referred to as machine learning or ML (Machine Learning). The data used by AI when performing machine learning is called training data. The term annotation, which is often seen, refers to the process of creating training data.
Now, let's clarify the terminology.
AI: Refers to artificial intelligence itself.
Machine Learning: Training that improves the accuracy of AI.
Training Data: Data used for machine learning.
Annotation: The process of creating training data.
The role of annotation in the AI development process is as follows.

1-2. Essential Training Data for AI Learning
Training data, as the name suggests, is the data that serves as a teacher when AI is learning.
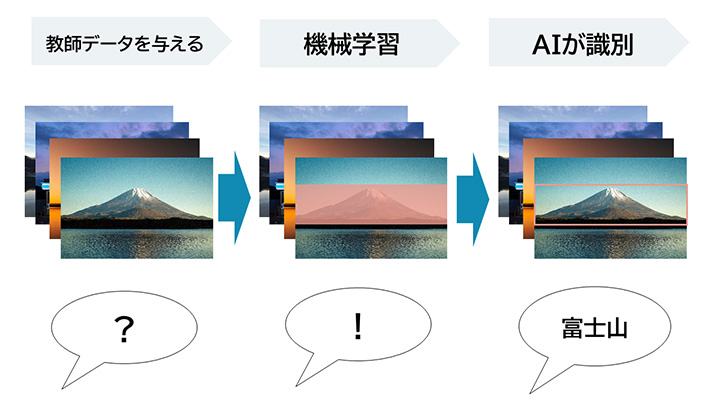
For example, a human shows an AI a picture of "Mount Fuji" and teaches it both the question "What is this?" and the answer "This is Mount Fuji." The AI is shown a large number of pictures of Mount Fuji repeatedly. As a result, the AI gradually learns to recognize "Mount Fuji," and the accuracy of its answers when asked "What is this?" improves, with responses like "This is Mount Fuji" and "This is not Mount Fuji." The data that includes the questions and answers shown to the AI is called training data. Just like humans, the more the AI learns, the higher its accuracy becomes. To further improve the accuracy of the AI, it is necessary to repeatedly train it using a sufficient amount of training data.
Next, we will explain the annotation work for creating training data.
1-3. Time-Consuming Annotation
Annotation is performed manually, requiring workers to possess not only accurate knowledge and judgment but also considerable perseverance. Behind the increasing capabilities of AI, this diligent process always exists.
In image data annotation, annotators manually specify certain areas within the images to add information. In the example of Mount Fuji above, the task involves visually inspecting each image and accurately selecting only the area where Mount Fuji is depicted.
1-4. How much quantity is needed?
How much training data is necessary? The answer varies depending on the project's objectives and the desired level of accuracy. We will actually train the AI with the available data to verify whether that amount can solve the issues or if further training is needed. If it seems insufficient, we will add more training data and continue the learning process. If it still does not work well, we may need to reconsider the rules for creating the training data. It is essential to consider both the quantity and quality of the training data.
1-5. What is the difference between teacher data and training data?
Here, we will explain the difference between training data and learning data.
:Training Data
A set of data labeled through annotation is called training data. AI learns the objects it should recognize based on this data. Even if it learns only from labeled data, whether it can accurately recognize unlabeled data cannot be evaluated by training data alone.
:Training Data
Training data refers to the entire set of data used by AI for learning. It includes unlabeled data in addition to labeled training data. AI that has learned the targets to recognize from labeled data improves its recognition accuracy through unlabeled data. Additionally, depending on the learning method, there are training data sets without labeled data.
1-6. Three Approaches to Machine Learning
Here, we will explain three representative approaches to learning methods used in machine learning.
1. Supervised Learning
Supervised learning is a method that uses training data containing labeled correct answers. It is mainly used in AI development and requires annotation work to create the training data. Supervised learning is commonly used for object detection.
2. Unsupervised Learning
This method uses training data that does not include labeled data. It identifies patterns within the data and classifies the data according to those patterns. This approach is often used for AI training aimed at anomaly detection and similar purposes.
3. Reinforcement Learning
Reinforcement learning is a method where the system repeatedly tries and errors by itself to find the optimal solution. It is a technique used when the task has clearly defined rules and an optimal solution can be sought. Common examples include AI that wins in robot control and games like chess.
2. Why is the quality of training data considered important?
2-1. What is High-Quality Training Data
The quality of training data greatly affects the accuracy of AI. High-quality training data requires both unbiased materials and consistent annotations. For example, if you are training AI to recognize Mount Fuji, it is necessary to prepare a variety of Mount Fuji photos taken from different locations and times of day without bias, rather than just similar photos. On the operational side, it is important to establish clear rules so that all annotators work based on the same criteria.
The high-quality training data referred to here does not necessarily mean that the annotation accuracy is high (e.g., segmenting as smoothly as possible along the contours of the target object, fitting bounding boxes within one pixel of the object, etc.). What is important is whether the annotation is properly performed based on work instructions or specifications that define the necessary requirements. For example, in a task where cars are enclosed with bounding boxes, if the specifications state that "some margin is allowed," then as long as the bounding box falls within the acceptable range without perfectly fitting the object, the data can be considered high quality.
High quality means "meeting the specifications," and it does not necessarily equal "high accuracy." Trying to increase accuracy beyond what is necessary will also increase the workload. In that case, not only quality but also the development schedule may be affected, causing delays and other issues.
2-2. Why is the quality of training data emphasized?
Even if you can define requirements aligned with the purpose of AI development, AI training will not succeed if the quality of the training data is low. If AI learns from low-quality training data, it will likely fail to achieve the accuracy needed for the development goals. In such cases, re-annotation becomes necessary. Often, the same annotators cannot be assigned again, requiring retraining of annotators. Additionally, not only does data need to be recreated, but related ancillary tasks also increase, leading to higher operational costs and potential project delays. If the training data is high quality from the start, it becomes possible to develop AI that meets the objectives while minimizing costs and accelerating the development cycle.
Next, we will explain how to create training data.
3. Procedure for Creating Training Data
In AI development, the quality of training data greatly influences the performance of the model. To create training data efficiently and with high quality, it is important to follow several steps and proceed systematically. Below, we explain the basic process of creating training data divided into four steps.
3-1. Clarification of Purpose
The first step is to clearly define the objective of what you want to achieve with the AI model. For example, when performing car image recognition, the required data and annotation methods (such as image classification or bounding boxes) will vary greatly depending on whether the goal is "identifying the car model" or "determining the presence of a car." By clarifying the objective at this stage, you can proceed with the subsequent processes without deviation.
3-2. Definition of Required Annotation Requirements
Once the objective is clear, the next step is to define the requirements for the annotations needed to achieve it. This includes specifying which annotation methods to use, what attributes and labels are necessary, and the level of granularity for the work, all compiled into specifications and work manuals.
By clearly defining policies in advance, you can prevent quality variations and rework, leading to smooth operations.
3-3. Data Collection
We collect actual data according to the defined requirements. There are various options for data collection methods.
Utilization of Internal Data: Use data already owned
Open Datasets: Utilize publicly available datasets
New Data Collection: Acquire data independently through filming or recording
Purchase of Datasets: Buy from external sources as needed
Furthermore, if only a small amount of data can be prepared, utilizing data augmentation, such as flipping or processing images to increase variations, is also effective. Consider the balance of the required amount and quality for training, as well as costs and labor, to choose the optimal method.
3-4. Implementation of Annotations
Once the data is collected, we perform the necessary preprocessing for annotation tasks. For example, unifying image formats (e.g., converting all to JPEG), applying naming conventions to files (such as sequential numbering or adding dates), and so on. Additionally, selecting the appropriate annotation tools for the task is also an important point.
We secure workers and start the annotation work after sharing and explaining the work manuals. During the progress, quality control such as managing progress, responding to questions that arise during the work, and checking annotation results is required. By properly conducting these operations, we can ensure the accuracy and consistency of the entire training data.
[Related Links]
>How to Ensure and Improve the Quality of Training Data? Practical Methods Explained!
4. Three Key Points in Producing Training Data

4-1. Standardization of Work Rules
AI cannot learn if the quality of the training data is inconsistent. Just like humans, if multiple teachers each teach different things, it becomes unclear whose instructions to follow. To prevent this, it is important in annotation projects to create a detailed work manual before starting the actual tasks and share it with the entire team. For more challenging projects, a trial period is sometimes set up initially, and only annotators who pass the test are assembled into the team.
4-2. Management System Suitable for Annotation
Annotation work requires considerable carefulness and perseverance. Furthermore, it demands a correct understanding of the work manual as well as knowledge and insight into the subjects being tagged. In terms of resources, not only the annotators responsible for the work but also checkers who verify the deliverables, trainers who provide education, and project managers who oversee the entire process are necessary. Building an effective management system tailored to the characteristics of the project leads to ensuring quality and productivity.
4-3. Ensuring Security Levels
Annotations may involve handling highly confidential data and personal information. Therefore, security training for annotators is essential. At the same time, it is necessary to implement adequate security measures in the construction of the work environment and the selection of tools used. When outsourcing annotation projects to external service providers, it is crucial to thoroughly verify the level of security measures of the outsourcing partner.
5. Human Science Teacher Data Creation and LLM RAG Data Structuring Outsourcing Service
Over 48 million pieces of training data created
At Human Science, we are involved in AI model development projects across various industries, starting with natural language processing, including medical support, automotive, IT, manufacturing, and construction. Through direct transactions with many companies, including GAFAM, we have provided over 48 million high-quality training data. We handle a wide range of training data creation, data labeling, and data structuring, from small-scale projects to long-term large projects with a team of 150 annotators, regardless of the industry.
Resource management without crowdsourcing
At Human Science, we do not use crowdsourcing. Instead, projects are handled by personnel who are contracted with us directly. Based on a solid understanding of each member's practical experience and their evaluations from previous projects, we form teams that can deliver maximum performance.
Not only for creating training data but also supports the creation and structuring of generative AI LLM datasets
In addition to creating labeled and identified training data for data organization, we also support the structuring of document data for generative AI and LLM RAG construction. Since our founding, we have been engaged in manual production as a primary business and service, leveraging our unique know-how gained from extensive knowledge of various document structures to provide optimal solutions.
Secure room available on-site
Within our Shinjuku office at Human Science, we have secure rooms that meet ISMS standards. Therefore, we can guarantee security, even for projects that include highly confidential data. We consider the preservation of confidentiality to be extremely important for all projects. When working remotely as well, our information security management system has received high praise from clients, because not only do we implement hardware measures, we continuously provide security training to our personnel.


































































































