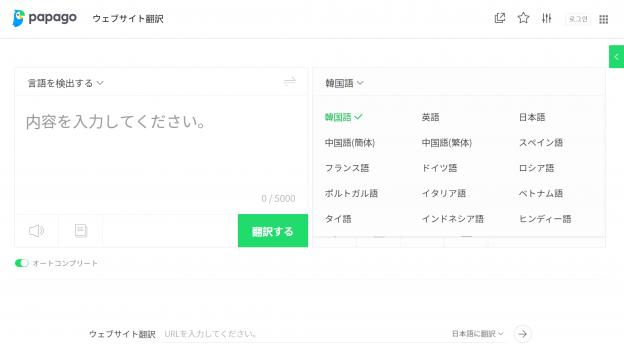
Google翻訳がニューラルネットワークの仕組みを日本語にも適用し、
翻訳精度が飛躍的に向上した、ということが、先日から大きな話題となっています。
ニューラルネットワークについては、9月の終わりに、
機械翻訳が苦手とする中国語から英語への機械翻訳への採用が始まっていました。
それが11月になって、日本語を含む8言語(韓国語、英語、
フランス語、ドイツ語、スペイン語、ポルトガル語、トルコ語)に採用されると、
日本国内のユーザーから、従来の Google 翻訳と比べて
大きな品質の向上がみられる、と驚きの声が挙がっています。
では、そもそも、ニューラルネットワークとは一体なんなのでしょうか?
●ニューラルネットワークとは
ニューラルネットワークとは、
人の脳内にある「ニューロン」の働きをまねた仕組みです。
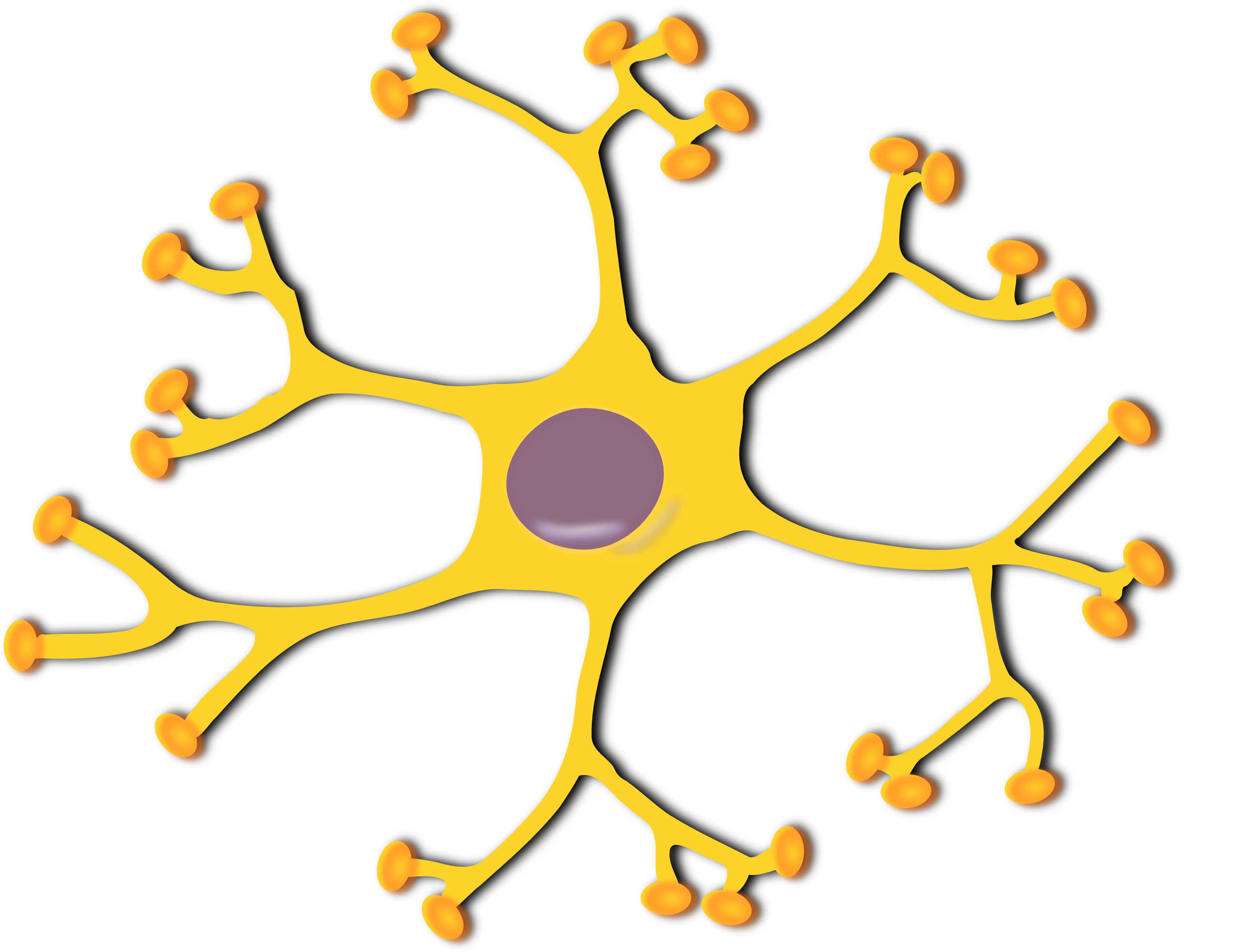
今まで、機械における「学習」というと、
あるインプットを与える→ある結果をアウトプットする
という、非常に単純なものでした。
機械翻訳でいうと、従来の統計ベースのエンジンに
コーパスを読み込ませる「トレーニング」が
この仕組みにあたります。
それに対してニューラルネットワークでは、
単純なインプット→アウトプットという流れにはなりません。
あるインプットが与えられると、
それまでにネットワークに読み込まれていた
他のデータと結び付けることによって、
その新しくインプットされたものがなんであるかを認識することができます。
これは、人が何か新しい物を学習しようとする時、
過去の経験に照らして似たようなものを連想することで、
その新しい物がなんであるかを認識しようとする働きに倣っています。
先日ニュースをにぎわせた囲碁プログラム「AlphaGo」を例にしますと、
コンピュータに囲碁を覚えさせようとすると、
従来型の学習であれば、「こういう手がきたら、こう返す」という
データを読み込ませる必要がありました。
これに対し、ニューラルネットワークの場合は、
大量の棋譜のデータを読み込ませることになります。
そうすると、ある手を差された場合、
過去の棋譜データにある似た局面からどういう手を返していたかの候補を探してきて、
そのなかでも有利に展開した棋譜データから得られた候補を採用します。
これが、ニューラルネットワークのごく簡単な説明です。
「厳密に言えば少し違う」という部分もあるかと思いますが、
概ねの理解としては参考にしていただけるでしょう。
方法論としては、1960年代に既に一度注目されたモデルになりますが、
技術の進歩によって大容量のデータを保管・処理が出来るようになったことで、
近年になりこれが実現可能になってきました。
●ニューラルネットワークを活用した機械翻訳の広がり
Google に続いて、Microsoft も、
機械翻訳にニューラルネットワークを採用することを発表しました。
前より、ニューラルネットワークを活用した機械翻訳の研究は進められていましたが、
ここにきて、私たちユーザーの身近になり、実際に使用出来るレベルになってきました。
今後も、ニューラルネットワークを活用した品質の向上に期待が高まります。
●まとめ
今回は、機械翻訳のブレークスルーとして注目を集めている、
ニューラルネットワークについてお話ししてきました。
ヒューマンサイエンスでは、これからも、
ニューラルネットワークを含む新たな技術の機械翻訳への
活用に目を向けていきたいと考えています。
今後の新技術情報にも、是非ご注目ください。
フォームが使用できない場合は、hsweb_inquiry@science.co.jp宛に
お問い合わせ内容をメールにてお送りください。
もしくはお電話TEL:03-5321-3111にてお気軽にご連絡ください。
関連記事
【市場動向】人間を超える?人工知能によるデータ処理
http://www.science.co.jp/mt/market/blog23.html