Voice Recognition QA Testing
With the advent of iPhone's Siri, Google's Google Now, Microsoft's Cortana, and more recently, Amazon Echo, voice recognition technology has become more accessible.
Now that voice recognition technology is receiving even more attention, Human Science, based on its long-standing achievements as a localization vendor, offers QA for voice recognition, QA seminars, and QA training, supporting our customers' services that utilize voice recognition technology.
What is Voice Recognition QA?
Speech recognition is a technology that enables computers to recognize human speech and convert it into text. Services (devices) that utilize this technology include Siri and Google Now, as mentioned earlier.
In speech recognition QA (Quality Assurance), we ensure the quality of "the computer correctly recognizing speech and accurately transcribing it" and "the device performing the expected actions based on the transcribed speech."
As voice recognition software, there are options like Dragon (by Nuance) and Speech Assistant (by Lyric), but the basic mechanism of voice recognition converts sound into 'phonemes' from 'sound waves', applies language information (words and grammar) to the 'phonemes', and converts it into 'text'. The voice recognition device then performs actions corresponding to this 'converted text'.
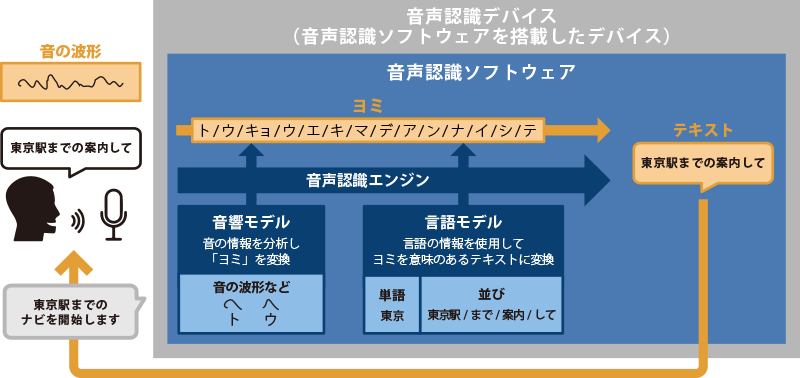
However, various factors such as noise from environmental sounds, the user's age and gender, and speech patterns can lead to the software misrecognizing speech and transcribing it incorrectly, or the device performing actions that do not meet the user's expectations. Therefore, ensuring that the computer correctly recognizes speech and accurately transcribes it, as well as that the device performs the expected actions based on the transcribed speech, is directly linked to user satisfaction.
Speech Recognition and Deep Learning
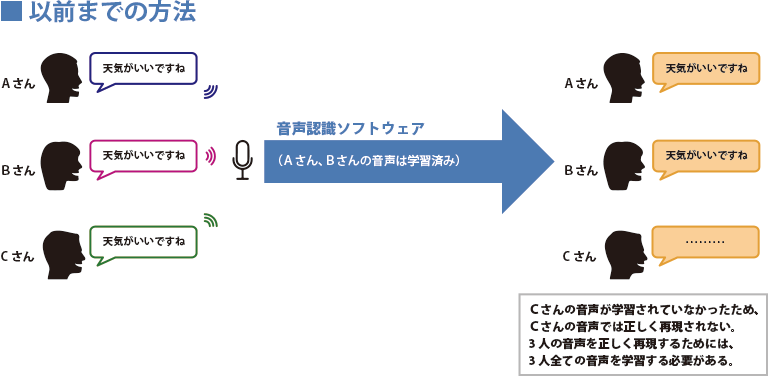
The field of voice recognition is also a very active area for deep learning. Previously, it was necessary to train on all utterances for each user, even if the same utterance was made by different users. However, with deep learning, by learning the patterns of utterances, it is possible to dramatically improve the recognition accuracy for utterances from different users.
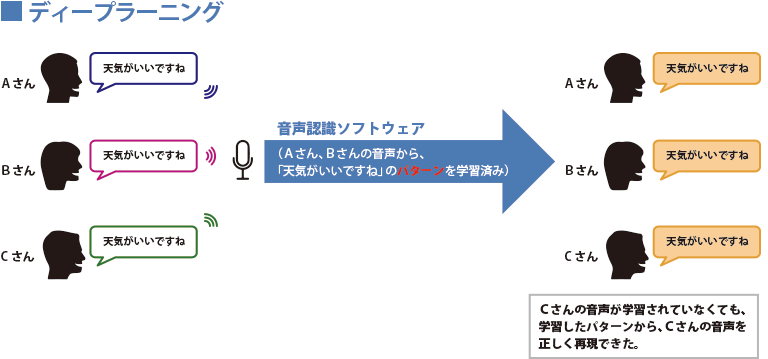
Deep learning is the best answer for improving speech recognition accuracy and is essential for enhancing user satisfaction with speech recognition services.
HS Voice Recognition QA
With years of experience in IT translation, Human Science contributes to improving software voice recognition accuracy and enhancing user satisfaction for our customers through the following voice recognition QA.
- - Quality management methods for services incorporating voice recognition
- - Improvement of existing voice recognition service quality - Efficient quality management methods
- ・In-house development of voice recognition QA
| Voice Recognition Analysis and Evaluation |
|---|
|
To achieve high-precision speech recognition, learning through deep learning is important, but the analysis and evaluation after training on speech patterns and technical terms are also very important. Analyzing and evaluating whether the speech patterns have been learned correctly and whether the recognition accuracy has improved after deep learning is an essential step for enhancing speech recognition.  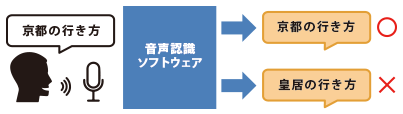 At Human Science, our experienced native Japanese speakers residing in Japan, who are registered with our company, work to accurately distinguish various regional and age-related Japanese speech, frequently used neologisms, industry terms, and technical jargon in IT, healthcare, and social media. We analyze and evaluate the recognition accuracy of software precisely. The results of the analysis and evaluation will be reported as quality improvement proposals, including issues, challenges, and their solutions. |
| User Experience Testing |
|
Once the user's speech has been correctly recognized, the next step is to have the device perform the appropriate actions in response. Essentially, the device executes the actions set for the "keywords" included in the speech. For example, a request like "I'm looking for a place where I can drink coffee" includes keywords such as "coffee," "drink," "place," and "search." The device selects and executes actions corresponding to these keywords. 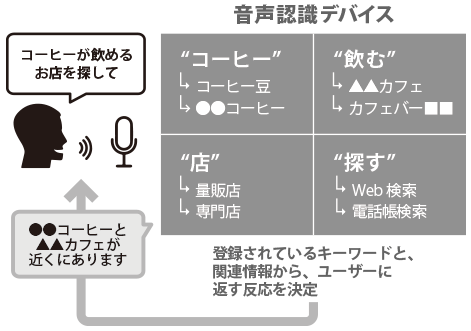 However, unfortunately, it does not always perform the actions that users expect. Most users who made this statement are likely to want to take a break while having a coffee at a café. However, how would the user feel if directed to a takeout-only coffee shop? If a coffee shop 100 km away is displayed, would the user go there? It is not incorrect to respond to "search for a place to drink coffee" even if it is a takeout specialty store or a store 100 km away. However, to scrutinize the user's intent and execute beneficial results for the user, meticulous testing by humans is necessary. Human science has experts who possess the necessary linguistic and cultural knowledge to interpret user utterances, We also have a Secured Access Room within the company, so you can confidently request product testing just before a high-security release. |
| Voice QA Seminar / Voice QA Training |
Based on the knowledge cultivated over many years as a localization vendor, we plan and propose QA seminars/QA training tailored to your service content and background. |
For those who want to know more about Translation and Localization into Japanese
- Reception hours: 9:30 AM to 5:00 PM JST
Tokyo: +81-3-5321-3111 Nagoya: +81-52-269-8016